Deep dive into malloc
malloc 은 어떻게 메모리를 할당할까? malloc 의 심해로 들어가보자.

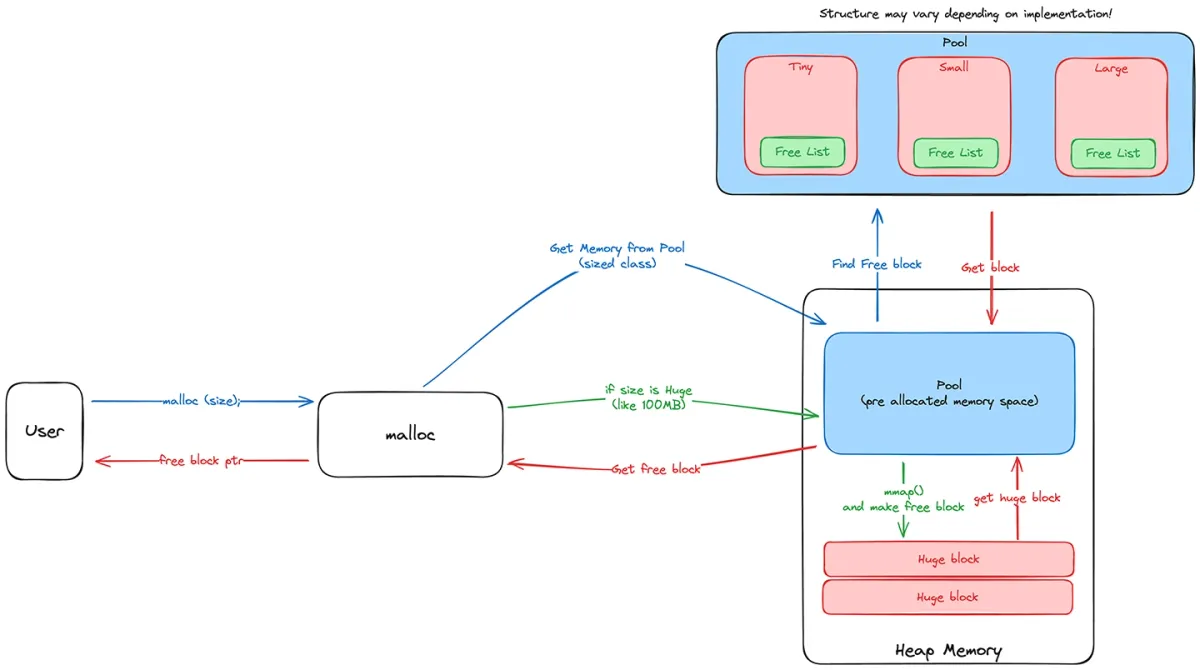
malloc 은 어떻게 작동하는 것일까요? malloc을 직접 만들어보면서 작성한 글입니다.
서론
메모리는 컴퓨터 시스템의 가장 핵심적인 자원 중 하나로, 이를 효과적으로 관리하는 것은 프로그램의 성능과 안정성에 결정적인 영향을 미칩니다. 메모리 관리의 중요성에 대해 대부분의 프로그래머들은 인지하고 있지만, 그 뒤에 숨겨진 복잡한 메커니즘들을 완전히 이해하는 것은 쉬운 일이 아닙니다. 이 글을 통해 이 복잡한 메커니즘을 동적 메모리 할당 함수인 'malloc'으로 시작하여, 실제 운영체제가 메모리를 어떻게 할당하고 관리하는지, 또한 CPU 캐싱이 메모리 접근에 어떤 영향을 미치는지를 살펴보며 하나하나 풀어나가보겠습니다. 이 글에서 소개하고 있는 키워드의 하나 하나가 깊은 내용을 담고 있기에, 깊게 들어가기보다는 개념과 흐름을 알아가보는 형식으로 진행하겠습니다.
메모리 구조
- 이미 메모리 구조에 대한 이해가 있으시다면, 해당 chapter는 건너 뛰셔도 됩니다!
메모리 할당에 들어가기에 앞서, 잠시 프로세스의 메모리 구조에 대해서 아주 가볍게 살펴봅시다. 각 프로세스는 각자의 가상 메모리 주소 공간을 할당받습니다. 그리고 아래와 같은 구조를 가지게 됩니다. (아주 단순화해서 표현한 모습입니다.)
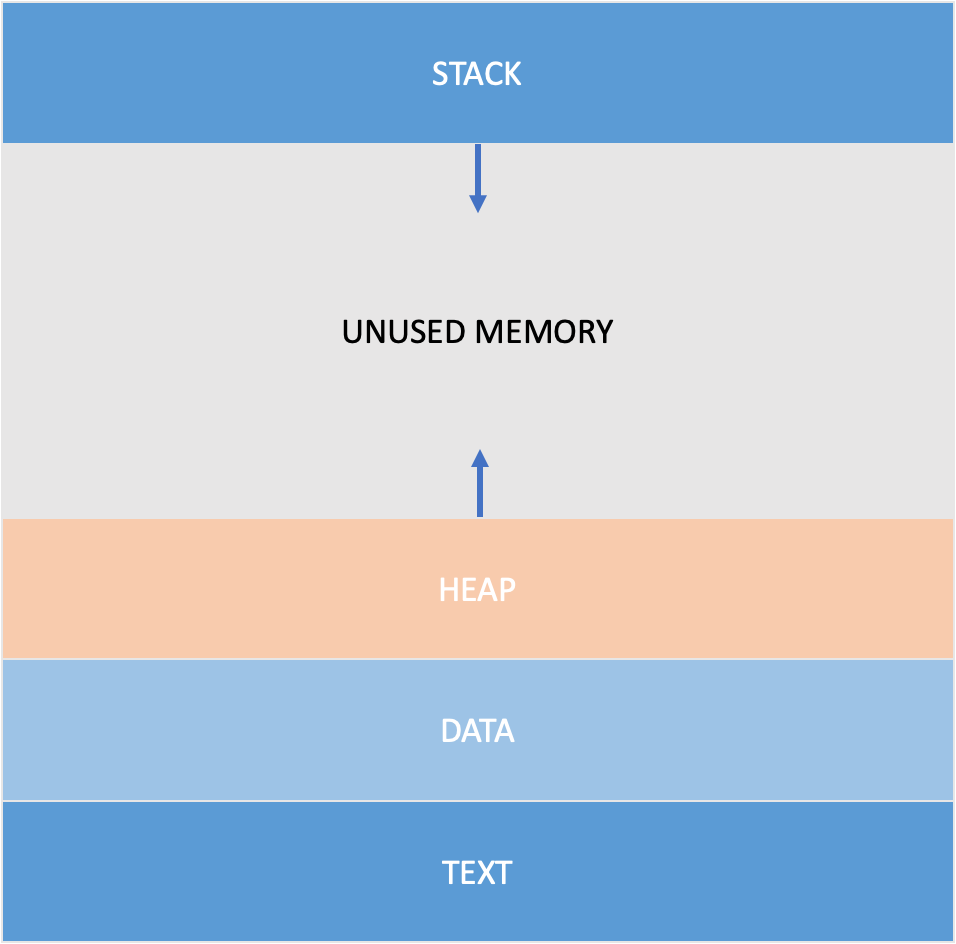
프로세스의 메모리 구조는 크게 TEXT, DATA, STACK, HEAP 영역으로 나뉩니다. 프로그램이 실행되어 프로세스가 메모리에 올라오게 되면 위와 같은 구조로 데이터들이 나열되어있다는 의미입니다.
(아래 설명은 GPT의 도움과 함께 작성되었습니다. 저보다 이 친구의 설명이 더 깔끔하네요…)
TEXT
해당 영역에는 프로그램의 실행 코드가 저장됩니다. 주로 기계어 명령어로 구성되어 있습니다. 텍스트 영역은 읽기 전용이며, 실행 시간에 변경할 수 없습니다.
- 해당 영역은 프로그램의 코드를 저장하고 있기에, 같은 프로그램이 여러번 실행할 경우 해당 영역의 실제 물리적 메모리 공간이 공유되어 메모리의 낭비를 줄입니다.
DATA
해당 영역에는 전역 변수와 정적 변수가 저장됩니다. 이 영역은 프로그램의 수명 동안 계속 존재하며, 두 부분으로 나뉘어집니다.
- 초기화된 데이터 세그먼트
- 프로그램 시작 시 초기값이 할당된 전역 및 정적 변수가 저장됩니다.
- 초기화되지 않은 데이터 세그먼트(BSS, Block Started by Symbol)
- 초기값이 할당되지 않은 전역 및 정적 변수가 저장됩니다.
STACK
이 영역에는 함수 호출과 관련된 정보가 저장됩니다. 이 정보에는 지역 변수, 함수 매개 변수, 반환 주소 등이 포함됩니다. 스택은 LIFO(Last In, First Out) 방식으로 작동합니다. 즉, 마지막에 들어온 항목이 가장 먼저 나갑니다. 함수 호출이 이루어질 때마다 새로운 스택 프레임이 생성되며, 함수 호출이 완료되면 해당 스택 프레임이 삭제됩니다.
HEAP
이 영역은 동적 메모리 할당에 사용됩니다. heap은 프로그램이 실행되는 동안 크기가 변하며, 프로그램은 malloc, calloc, realloc 등의 함수를 사용하여 heap에서 메모리를 할당하거나 해제할 수 있습니다. heap은 구조화되지 않은 메모리 영역으로, 프로그램이 필요한 만큼 언제든지 메모리를 할당하거나 해제할 수 있습니다. (*물론 heap overflow 상황이 발생할 수 있습니다.)
이번 글에서는 주로 heap 영역을 살펴볼 것입니다. 그러면 본격적으로 메모리 할당은 무엇이고, 어떻게 일어나는지 알아봅시다.
메모리 할당
메모리는 우리가 작성한 프로그램이 실행되기 위한 데이터와 명령어를 저장하는 공간입니다. 이러한 메모리 공간은 정적 메모리 할당과 동적 메모리 할당, 두 가지 주요 방식을 통해 관리됩니다. 다시, 위에서 본 그림과 예시코드를 통해서 살펴봅시다.
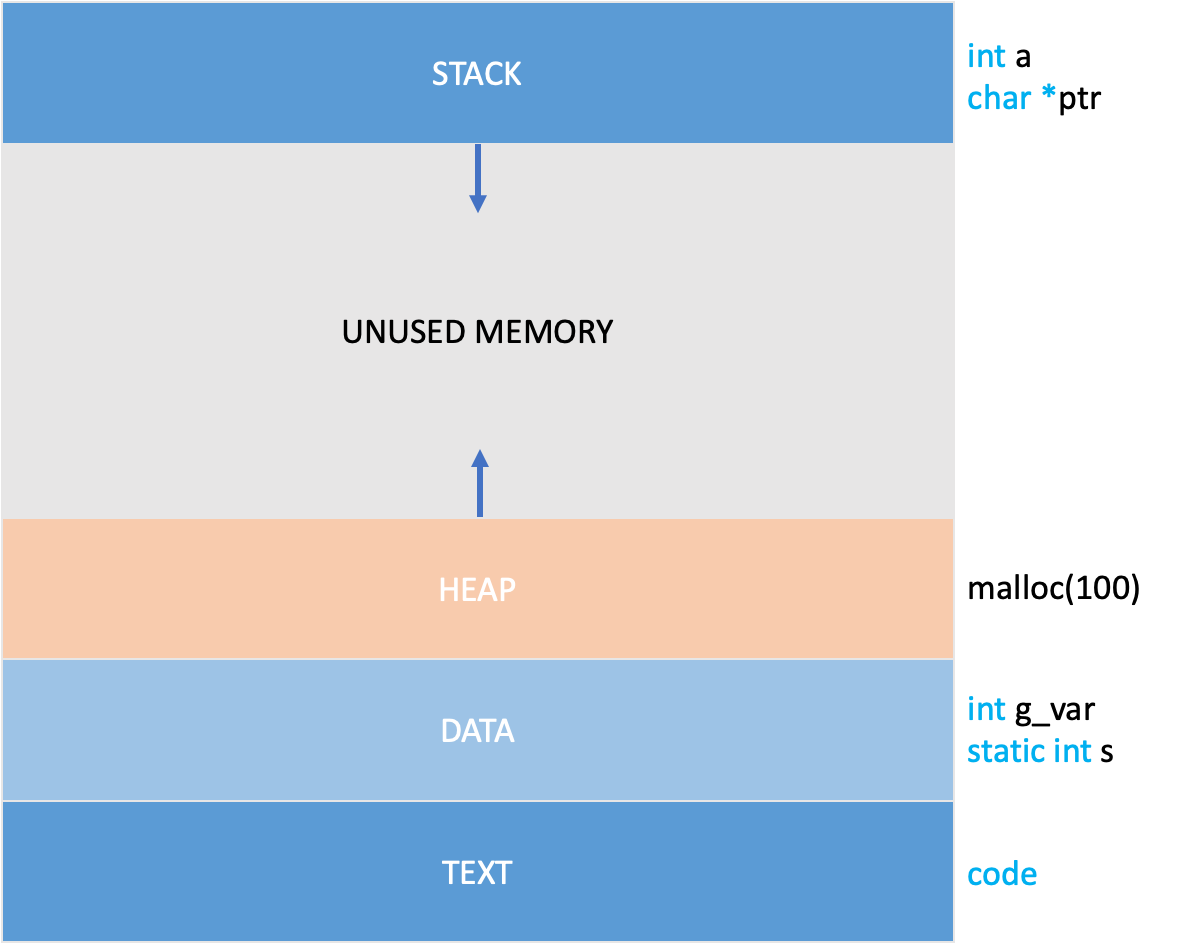
int g_var; // static memory allocation (will be stored in data section)
int main() {
static int s = 1;
int a = 0; // static memory allocation (will be stored in stack)
char *ptr = malloc(100); // dynamic memory allocation (will be stored in heap)
}
정적 메모리 할당
정적 메모리 할당은 컴파일 타임에 이루어집니다. 프로그램의 실행 과정에서 그 크기가 변경되지 않습니다. Data 영역에 속하는 전역 변수 ‘int g_var’, static 변수 ‘int a’ 등이 여기에 속하며, 함수의 실행과 함께 stack에 쌓이는 변수인 ‘int a’, ‘char *ptr’도 이에 해당된다고 할 수 있습니다.
동적 메모리 할당
반면에 동적 메모리 할당은 런타임에 이루어지며, heap 공간에 할당됩니다. 이 데이터들은 프로그램이 실행되는 동안 그 크기나 생명 주기를 유연하게 변경할 수 있습니다. 우리 코드에서는 ‘malloc’을 통해 할당된 100 바이트의 공간이 이에 해당됩니다.
동적 메모리 할당은 프로그램이 필요한 만큼의 메모리를 할당하고, 더 이상 필요하지 않게 되면 해당 메모리를 해제하는 방식으로 작동합니다. 그리고 이들은 ‘heap’ 이라고 부르는 영역에 저장이 됩니다. 이를 가능하게 하는 것이 바로 'malloc'와 같은 메모리 할당 함수입니다. C 언어에서 'malloc' 함수는 요청된 크기의 메모리 블록을 할당하고, 그 메모리 블록의 주소를 반환합니다. 반면에 'free' 함수는 이전에 할당된 메모리 블록을 해제하는 역할을 합니다.
malloc
‘malloc’과 ‘free’는 이러한 메모리 요청과 반환을 운영체제에게 전달하고, 이 과정에서 메모리를 보다 더 효율적으로 사용하고 빠르게 해당 요구를 수행할 수 있도록 합니다. 이는 구현에 따라 다르지만, 우리가 사용하는 대부분의 malloc은 최대한 빠른 속도로 유저에게 메모리 할당을 할 수 있도록 시스템 콜을 최소화하며, 주어진 메모리를 효율적으로 관리하는 역할까지 수행합니다.
우리는 이제 동적 할당을 통해서 메모리가 실제로 어떻게 할당되고, 위치하며, 관리되는지 알아볼 것입니다. 우리에게 친숙한 ‘malloc’ 을 알아보기에 앞서, 가장 낮은 수준의 할당 방법인 시스템 콜을 통한 메모리 할당을 잠깐 살펴봅시다.
시스템콜을 통한 메모리 할당
가장 저수준의 동적 메모리 할당의 경우 (UNIX 기준) mmap(), brk(), sbrk() 이 있습니다. 세 시스템콜 모두 heap 영역에 메모리를 할당하기 위해 사용되는 시스템콜입니다. 먼저 brk() 와 sbrk()를 가볍게 살펴봅시다.
brk(), sbrk()
#include <unistd.h>
int brk(void *addr);
void *sbrk(intptr_t increment);brk() 와 sbrk() 는 “program break” 를 조절하는 시스템콜입니다. program break 란 data segment 영역의 끝을 말합니다. (생각해보면 data segment는 heap과 이어져있습니다!) 이 break 를 늘리고 줄이는 과정에서 해당 시스템콜은 메모리 할당과 해제를 수행하게됩니다.
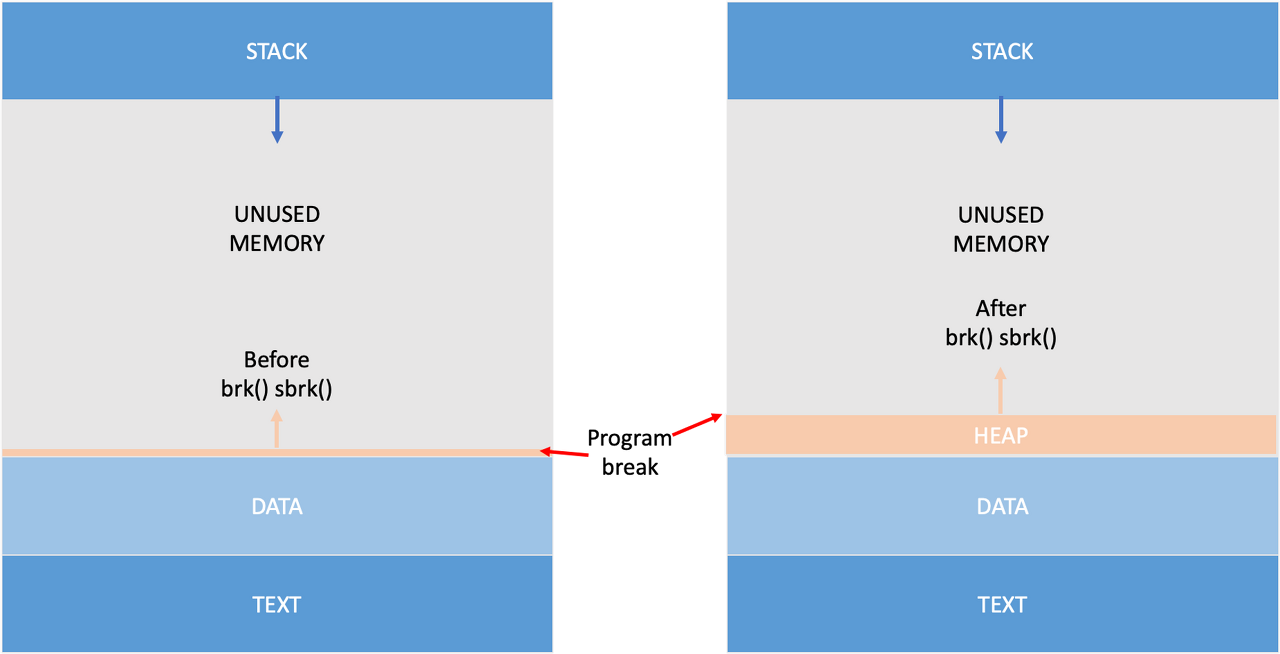
brk() 의 경우 addr 를 직접 명시하여 break 의 절대 주소를 직접 지정하는 반면, sbrk() 의 경우 increment 값에 의해 break 를 그만큼 늘리고 줄입니다. 우리가 흔히 보는 메모리 구조에서 heap이 data 영역에 붙어 자라나는 모습이 바로 이 시스템콜 덕분이라고 할 수 있겠습니다.
brk()와 sbrk()의 경우 오랜 기간동안 동적 메모리 할당 구현에 사용되었습니다. 그러나, 최근에는 아래의 이유들로 사용하지 않고 mmap()을 통해서 구현합니다. (아래 설명은 GPT로 작성되었습니다.)
- 연속적인 메모리 할당: **
brk**와 **sbrk**는 힙을 연속적인 방식으로 확장하거나 축소합니다. 이는 운영 체제가 효율적으로 메모리를 관리하거나 프로세스가 메모리를 유연하게 사용하는 것을 어렵게 만들었습니다. - 단편화: 메모리를 연속적으로 할당하면 메모리 단편화 문제가 발생할 수 있습니다. 즉, 메모리에 여러 개의 작은 빈 공간이 생겨 메모리를 효율적으로 사용할 수 없게 됩니다.
- 멀티스레딩과 호환성: **
brk**와 **sbrk**는 멀티스레딩 환경에서 안정성 문제를 야기할 수 있습니다. 다중 스레드 환경에서는 여러 스레드가 동시에 힙을 조작하려고 할 수 있으므로 동기화 문제가 발생할 수 있습니다.
- 위 설명에서 중요한 키워드 두 가지가 나왔습니다. 단편화와 멀티스레딩입니다. 해당 주제는 malloc의 구현과 역사에 밀접한 연관을 가지고 있습니다. 두 키워드를 꼭 기억해주셨으면 합니다.
mmap()
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
mmap은 단순히 함수의 인자만 봐도 brk, sbrk 보다 많이 복잡해보입니다. 실제로도 사용에 있어서도, 내부 동작도 다소 복잡한 시스템콜이지만, 핵심은 단순합니다. 핵심은 ‘운영체제로 하여금 원하는 메모리 페이지 매핑을 할당 요청한다’ 라는 것입니다.
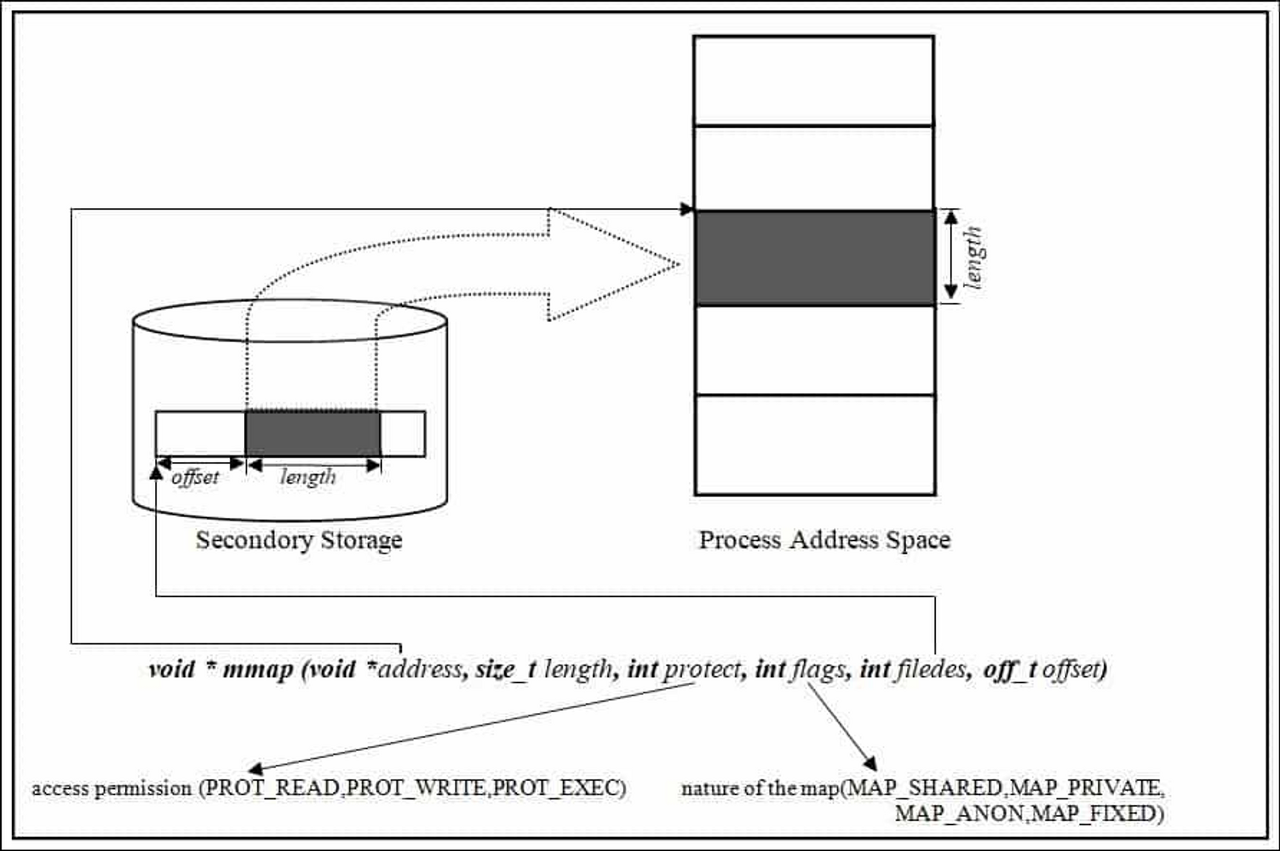
우리는 현재 물리적 메모리에 매핑을 요구하고 있지만, mmap을 통해 shared memory도 가능하고, 파일을 메모리에 매핑하는 것도 가능합니다. 그리고 mmap을 통해 할당된 모든 매핑은 추후 munmap() 이라는 시스템콜을 통해서 해제됩니다.
자세한 내부 사용법과 메뉴얼은 아래 페이지를 참고해주세요.

mmap을 통해서 메모리를 할당할 때는, 실제 메모리에 필요한 페이지의 크기 바이트 만큼을 요구하게 됩니다. 일반적으로 한 페이지는 4KB 의 크기를 갖고, 이 페이지 크기의 배수에 해당하는 값으로 요청하게 됩니다. 예를 들어, < 4kb 일때는 4kb, 5,000 byte 일 때는 8kb 이런 식입니다. 그 결과, 운영체제는 실제 메모리와 매핑된 페이지를 그만큼 할당하고, 반환합니다.
mmap을 할 때, 할당하고자 하는 가상 메모리 주소를 명시할 수도 있습니다. 이는 hint로 작용하여, 메모리는 그 근처에 메모리를 할당 할 수 있다면 메모리를 할당해줍니다. 하지만, 일반적으로 malloc 구현시에는 이 hint를 제공하지 않고, 운영체제에게 아무데나 공간을 할당해주도록 요청합니다. 이렇게 mmap을 통해 요청된 heap 은 연속적으로 배치가 되지만, 그렇지 않을 수도 있습니다. (뚝뚝 끊겨서 매핑된 공간이 존재할 수도 있습니다.)
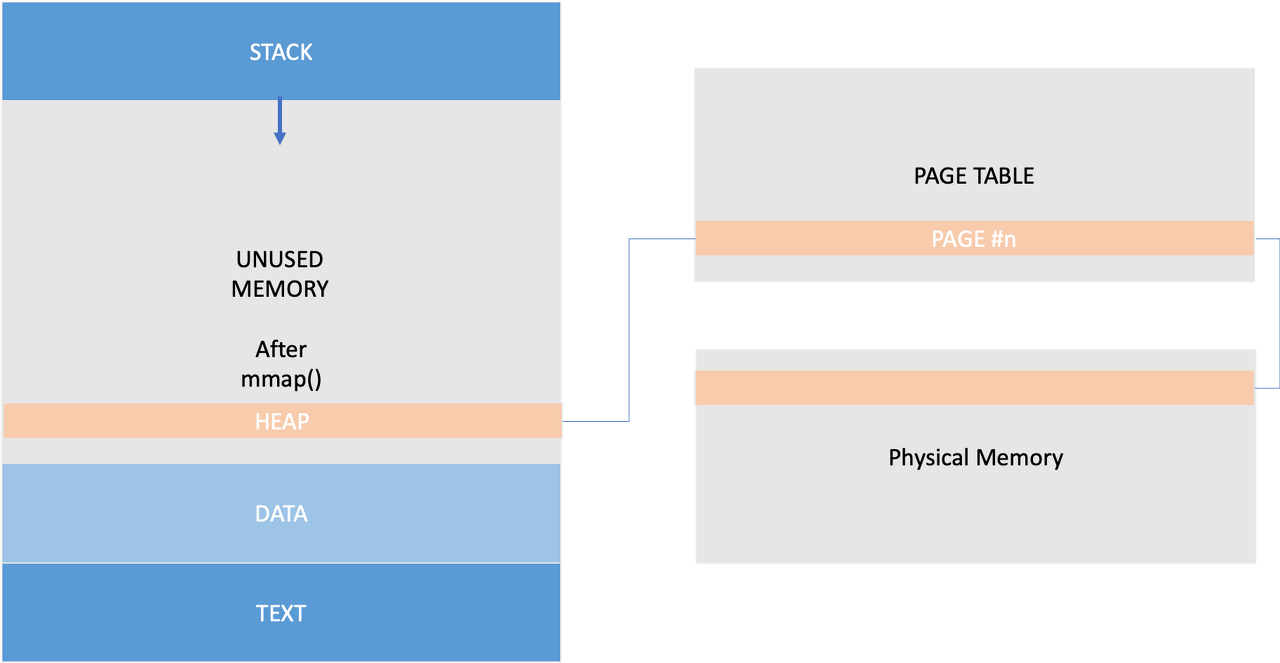
brk 에서도 마찬가지이긴 하지만, 페이지 단위로 메모리 할당을 요청한다는 것을 눈여겨볼 필요가 있습니다. 실제로 우리가 어떤 메모리를 필요로할 때, 운영체제는 1바이트 단위로 떼어서 내어주지 않습니다. 적어도 4kb 의 공간을 한번에 던져줍니다.
만약 정말 그렇게 사용을 한다면 무려 409,500%의 메모리 낭비가 일어날 것입니다. 그리고 더 안타까운 점은, 이렇게 부르는 시스템콜이 결코 값싼 작업이 아니라는 것입니다. 매번 느리고, 메모리 비효율적인 작업을 하지 않기 위해서 malloc은 똑똑하게 작동합니다. 매 동적 할당 요청마다 새로운 페이지를 가져오지 않고, 최대한 빠르고 효율적인 방법을 추구합니다. 이제 malloc은 어떻게 이 문제를 해결하고 있는지 본격적으로 살펴봅시다.
malloc
이제 드디어 malloc에 대해서 뜯어볼 차례입니다. 우리는 단순히 malloc 이라는 함수를 동적 할당을 해주는 하나의 api로 바라보고 사용해왔을 것입니다. 단순히 메모리를 요청하면, 그 만큼의 메모리를 반환한다. 그 정도만 알아도 프로그래밍을 하는데 큰 문제는 없으니까요. 그렇기에 뒤에서 어떤 일이 일어나는지는 잘 모르는 분들이 대부분일겁니다.
그런데, 놀랍게도 malloc은 단 하나의 구현만 존재하는 것이 아닙니다. 그 구현의 종류는 아주 다양합니다. 당장, mac에서 사용하는 malloc과 linux에서 사용하는 malloc의 구현이 다릅니다. 그리고 실제로 사용하는데 영향을 미칠만큼 꽤나 큰 차이점도 가지고 있습니다. 아래는 GPT 에게 물어본 malloc의 종류들입니다.
malloc의 종류
- glibc malloc: GNU C 라이브러리에 포함된 기본 malloc() 구현입니다. 그 이전에는 ptmalloc(Doug Lea's dlmalloc에 다중 스레드 지원을 추가한 버전)을 사용했었습니다.
- jemalloc: Firefox와 같은 많은 실시간 애플리케이션에서 사용되는 malloc() 구현입니다. 메모리 단편화를 최소화하려는 목표로 설계되었습니다.
- tcmalloc: Google에서 개발한 malloc() 구현으로, 빠른 스레드 로컬 캐시와 중앙 힙을 효율적으로 관리하려는 목표로 설계되었습니다.
- kmalloc: 리눅스 커널에서 사용되는 메모리 할당 함수입니다. kmalloc()은 물리적으로 연속적인 메모리 블록을 할당하는데 사용됩니다.
- dlmalloc: Doug Lea가 개발한 malloc() 구현으로, GNU C 라이브러리의 ptmalloc의 기반이 되었습니다.
- mimalloc: Microsoft에서 개발한 malloc() 구현으로, 효율성과 최적의 성능을 목표로 설계되었습니다.
- rpmalloc: 빠르고 경량화된 malloc() 구현으로, 게임과 실시간 시스템 등에 적합하도록 설계되었습니다
이렇게 malloc의 구현이 많은 이유는, 각자의 환경마다 요구하는 조건이 다르기 때문입니다. malloc의 내부 구조는 생각보다 복잡하기에, 구현에 따라서 특정 상황에 대한 성능이 차이날 수 있습니다. 이는 우리가 malloc에 대해서 깊게 알아봐야하는 이유 중 하나이기도 합니다.
위 malloc 에서 우리가 자주 마주하게 되는 malloc은 mac에서 마주하게되는 ‘jemalloc’ 과 linux에서 마주하게 되는 ‘glibc malloc’ 입니다. 앞으로 설명하는 malloc의 설명은 이 두 malloc의 구현과 많은 연관이 있습니다.
pool
앞서, 우리는 시스템콜을 살펴보며 운영체제에서 메모리를 할당받을 때 적어도 4kb 단위로 받아와야한다는 사실을 알게되었습니다. 그러면 우리는 malloc을 할 때 매번 새로운 페이지를 요청하는 것 일까요? 정답은 ‘대부분 그렇지 않다’ 입니다. 우리가 개발에 사용하는 malloc의 대부분은 이런 비효율성을 줄이기 위해 malloc 내부적으로 미리 할당된 메모리, pool을 가지고 있습니다. pool 에서는 일정 메모리 크기의 요청이 왔을 때, pool에 메모리가 남아있다면 새로운 메모리를 운영체제에게 요청하지 않고, malloc 내부에서 자체적으로 해당 블록을 반환합니다.이는 생각보다 꽤나 큰 차이를 만들어냅니다. 메모리 할당 / 반환이 빈번한 작업의 경우 특히 더 차이가 크게 발생합니다.
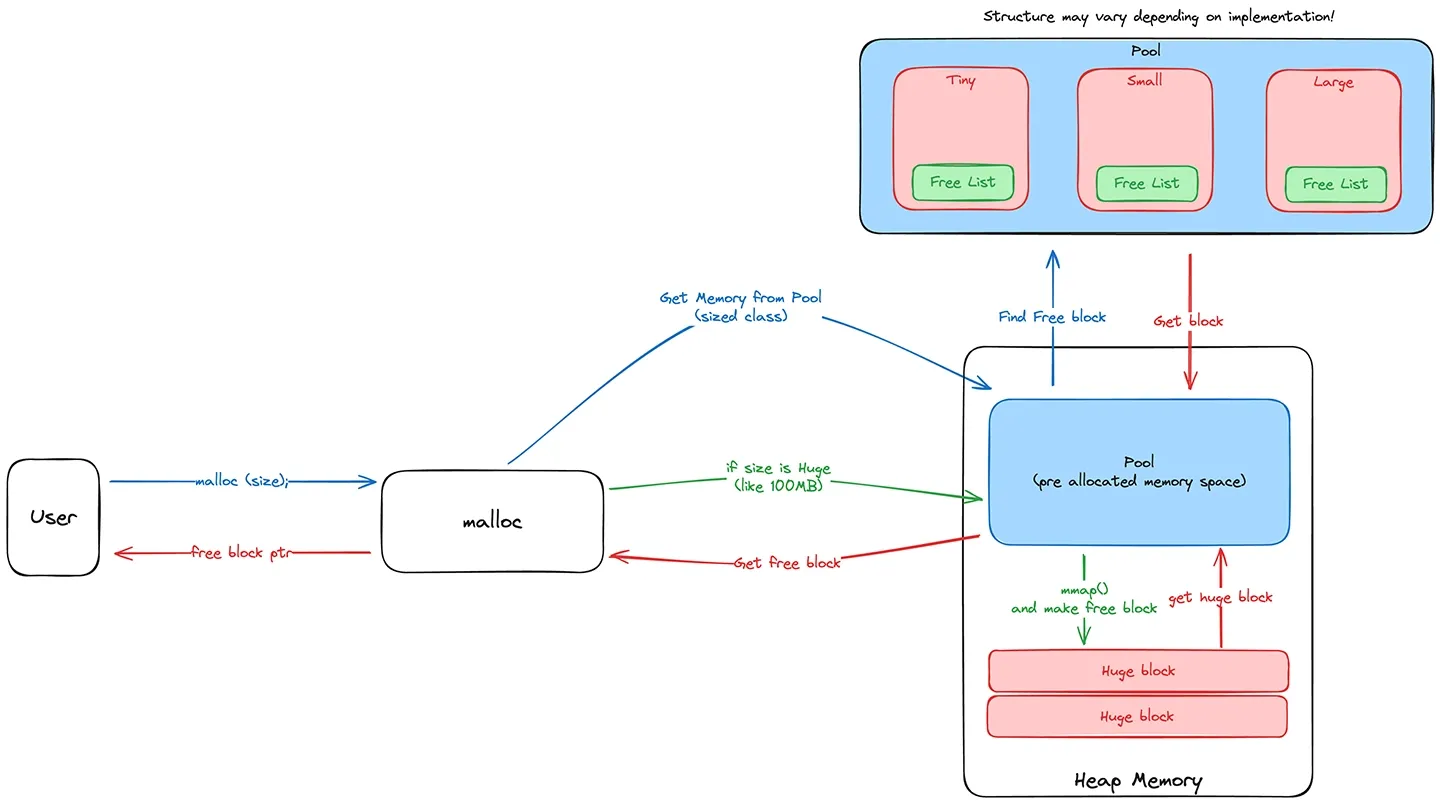

pool을 사용한다면, 이렇게 성능의 차이 뿐 만 아니라, 작은 메모리 할당에 대해서 메모리를 보다 더 효율적으로 사용할 수도 있습니다. 앞서 극단적 예시로 이야기했던 1byte 할당에 대한 이야기가 이에 해당합니다. 4kb의 공간을 미리 정해둔 사이즈의 메모리 블록으로 쪼개서 보관한다면, 할당 요구하는 메모리가 작더라도 그에 맞는 작은 공간을 내어주면 됩니다.
그러면 실제로 이 pool은 어떤 형식으로 구현이 되어있을까요? jemalloc의 구현을 한번 살펴봅시다.
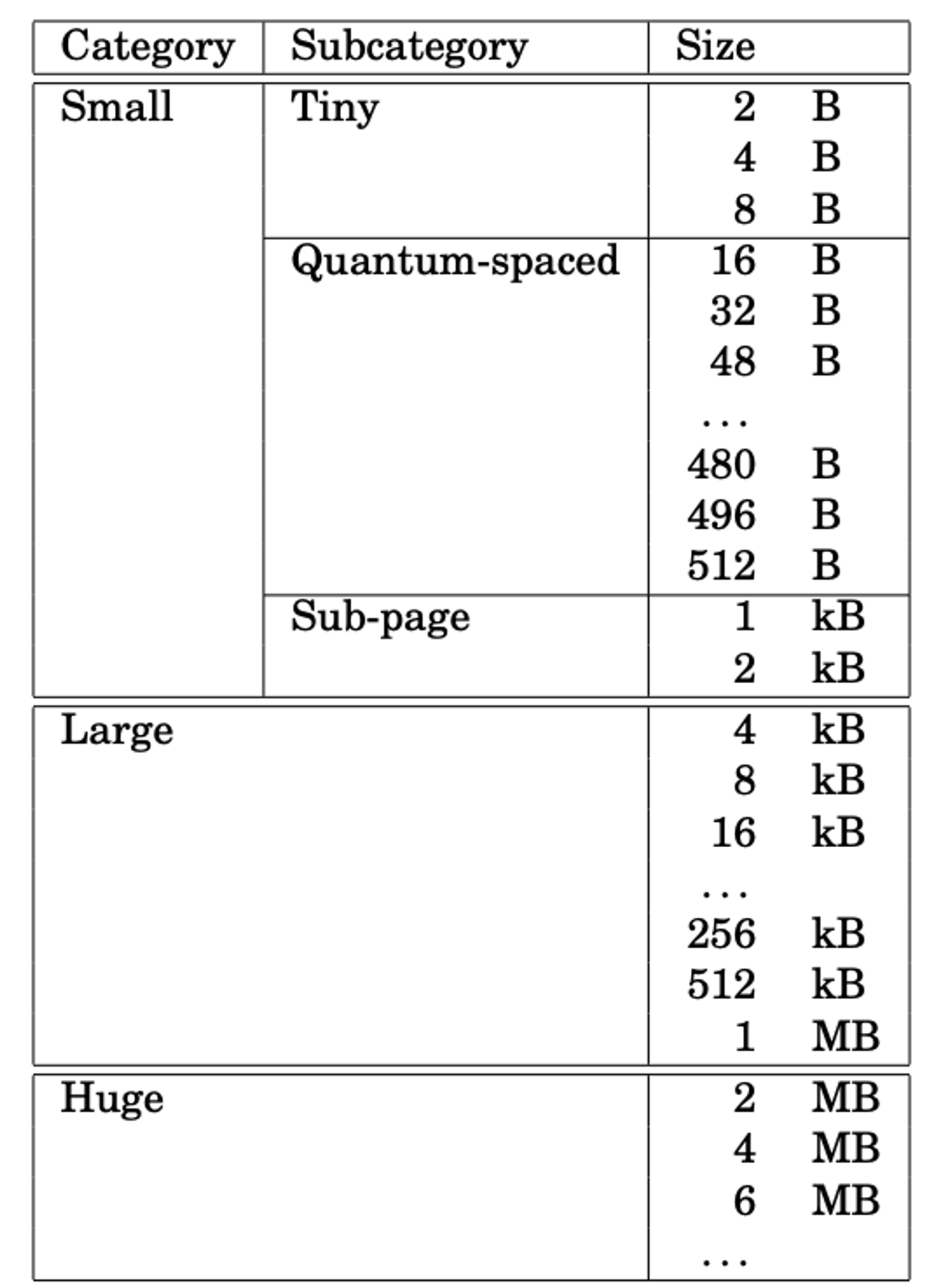
jemalloc은 크게 3개의 카테고리로 할당 사이즈를 분류합니다. (subcategory는 건너 뛰고…) small, large, huge 이며, small 의 경우 2kb 이하의 메모리 블록, large의 경우 1MB 이하의 블록, Huge는 그 이상의 블록입니다. 이 중 pool을 유지하고 있는 카테고리는 small과 large 입니다. 이 둘의 경우 해당 사이즈의 블록을 할당하기 위해서 미리 메모리를 할당해둡니다. 그 결과, 만약 small 혹은 large 사이즈의 메모리 요청이 오게 된다면, 그에 맞는 사이즈의 메모리를 내부적으로 바로 할당하여 반환해줄 수 있습니다. 이런 형태를 “slab allocator” 라고 하며, 내부 단편화를 줄이는데 톡톡한 역할을 수행합니다. 이는 각 malloc의 구현에 다르지만, subdcategory 별로 따로 분류를 하여, 각 사이즈에 맞는 블록을 세분화하여 관리하여 보다 더 효율적으로 관리할 수 있습니다. 또한, 메모리를 최대한 효율적으로 사용하기 위해서 일반적인 사용 패턴에 의거하여 미리 할당해두는 양을 각각 다르게 지정해둡니다. (적게 쓰는 용량은 적게, 많이 쓰는 용량은 많게…)
huge 의 경우 조금 다르게 작동합니다. 메모리의 요구가 들어왔을 때, pool에서 꺼내서 주기에는 너무나 큰 크기의 메모리입니다. 따라서, 이 경우에는 mmap() 과 같은 시스템 콜을 통해서 직접 할당을 하고 반환을 하게 됩니다.
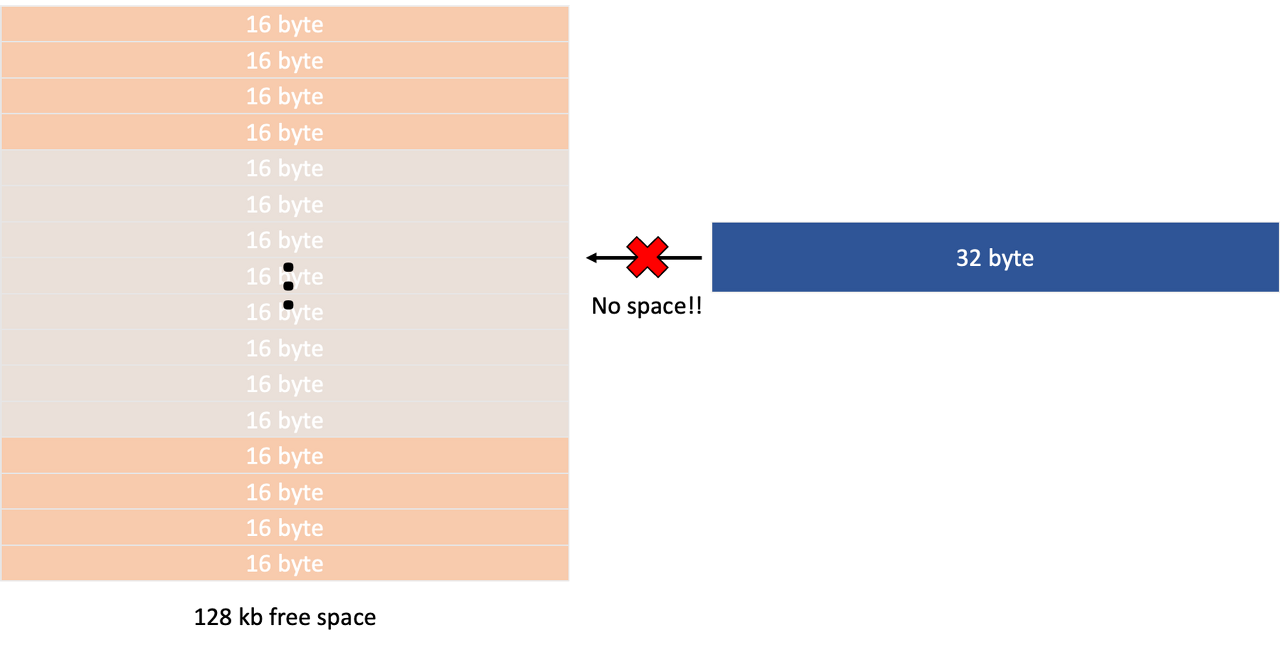
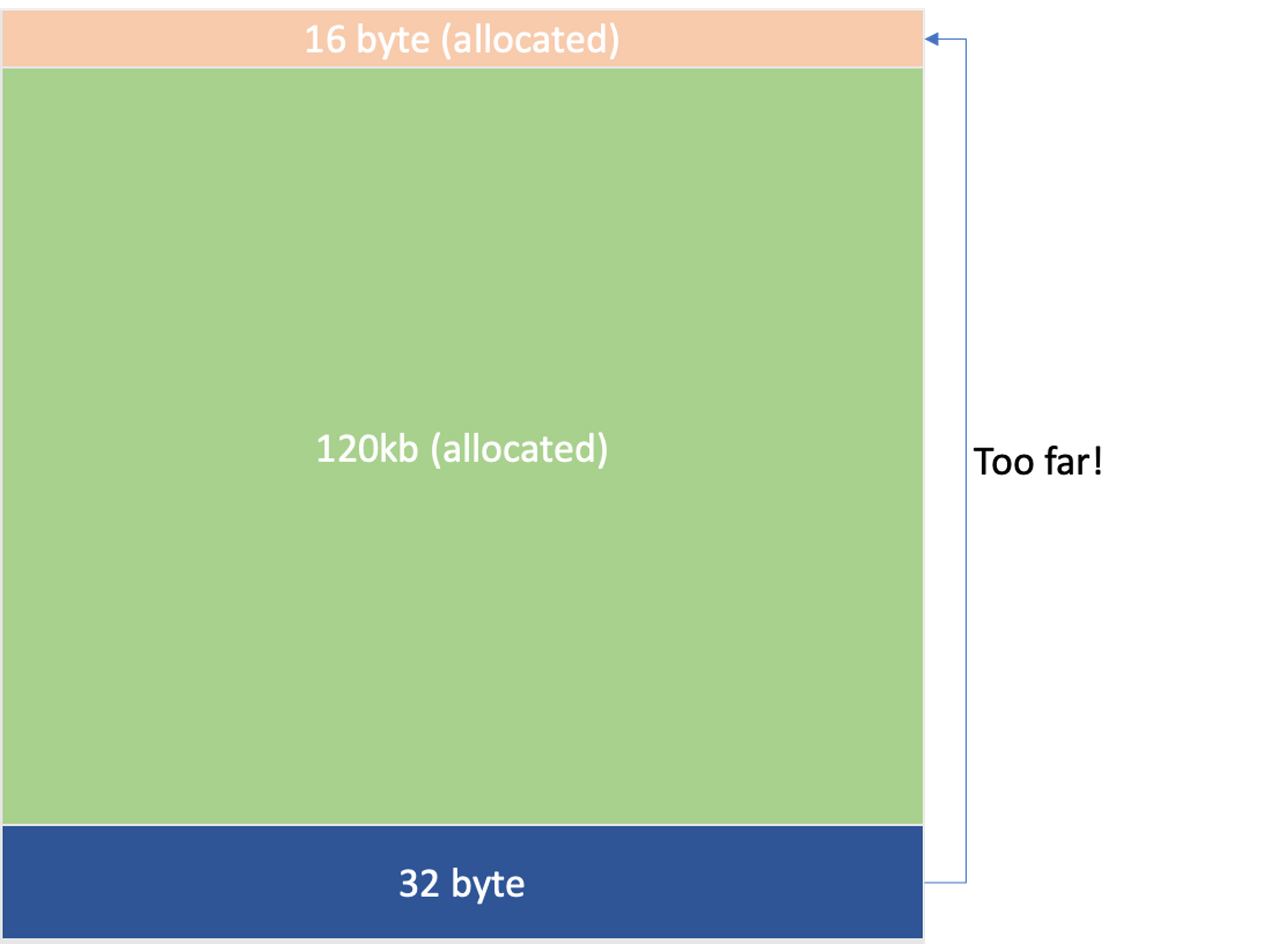
그런데 왜 사이즈를 나눠서 관리하게 되는 것 일까요? 이는 pool 마다의 정렬된 사이즈에서 비밀을 찾을 수 있습니다. 각 사이즈 카테고리는 일정 사이즈 만큼 정렬되어 있습니다. (페이징 기법에서 본 것과 비슷합니다.) 예를 들어, small의 경우에는 최소 16 바이트의 배수이고, large의 경우에는 4kb의 배수입니다. 이렇게 정렬을 하면, 메모리의 단편화를 줄일 수 있으며, 메모리의 공간적 지역성이 좋아집니다. 특정 크기의 블록들로 세분화하여 관리하면 작은 크기와 크기의 블록이 함께 공존하지 않으니, 그 효과는 더 증대됩니다. 하지만 그 만큼의 내부적 단편화가 발생할 수 있다는 단점을 안고 있기도 합니다.
여기서 잠깐 등장한 메모리 지역성과 단편화는 메모리 할당자의 구현에서 굉장히 중요한 지표이기도 합니다. 메모리 지역성이 좋은 할당자의 경우 성능상의 이득을 취할 수 있고, 메모리 단편화가 적을 경우 보다 더 메모리를 효율적으로 활용할 수 있습니다.
malloc에서 미리 할당된 메모리를 확보하고 있을 때, malloc은 보다 빠르게 작동할 수 있습니다. 사실, 실제 구현은 위에 설명한 것보다 더 복잡합니다. glibc malloc의 경우에는 가용 메모리 블록을 빠르게 접근할 수 있도록 몇 단계로 메모리 블록을 나누어 관리를 합니다. 그리고 이렇게 pool을 만들었다고 하더라도, pool에 어떻게 더 효율적으로 접근하고, 블록을 찾아낼 지에 대한 고민도 필요합니다. 여기서 문제가 하나 더 발생합니다. 우리는 할당된 메모리의 정보를 어떻게 추적하고 있는 것일까요? free(ptr) 을 했을 때, free는 어떻게 malloc 된 사이즈를 알고 해제를 하는 것일까요? 그리고 어떻게 남은 메모리 공간을 알고 있는 것일까요? 이 또한 마법처럼 일어나는 일이 아닙니다. 결국 할당되거나 해제된 각 메모리 공간에 대해서 정보를 담고 있어야합니다.
metadata
malloc에서 할당한 메모리는 다시 하나의 논리적 메모리 블록이 됩니다. 이렇게 논리적 메모리 블록으로 구성하기 위해서는 해당 메모리 블록에 대한 정보를 어디인가 저장해야합니다. 그 정보에는 이 블록이 할당된 블록인지, 아닌지에 대한 정보, 할당을 해제하기 위해서 해당 블록의 사이즈와 같은 정보와 같은 것들이 필요할 것입니다.
정보 저장 방법
이 블록에 대한 정보를 보관하는 방법은 크게 두 가지가 있습니다. 블록 내부에 그 정보를 저장하는 방법과, 블록 외부에 그 정보를 저장하는 방법입니다. glibc malloc의 경우 전자를 택하고 있고, jemalloc의 경우 후자를 택하고 있습니다. 이는 각각의 장단점이 존재하기 때문이기도 합니다.
block 내부에 해당 정보를 저장한다면, 단순히 블록의 주소만 안다면 해당 블록의 정보를 바로 찾아낼 수 있습니다. 또한 별도로 이러한 정보를 저장하기 위해서 별도로 메모리 공간을 따로 할당하지 않아도 된다는 이점을 가지고 있습니다. 반면, block 내부에 해당 정보가 존재하기 때문에 블록의 크기가 온전히 데이터를 기록할 수 있는 크기보다 커지게 됩니다. 또한, 논리적으로 존재하는 부분이기 때문에 해당 메모리 공간은 쓸 수 있기에 해당 공간 또한 유저의 부주의로 인해서 해당 데이터가 손상될 수도 있습니다.
block 외부에 정보를 저장하는 방법은 그 반대입니다. 해당 블록에 대한 정보를 알기 위해서는 해당 블록의 정보를 찾는 알고리즘이 필요합니다. 또한 이 정보를 별도로 저장하기 위해서 따로 메타데이터용 메모리 공간이 필요할 것입니다. 반면, 블록의 크기만큼 그대로 유저가 모두 사용할 수 있으며, 유저가 정보를 훼손할 위험으로부터 멀어질 수 있습니다.
어떤 정보를 담을까?
그러면 해당 정보에는 어떤 정보가 담겨있을까요? 이번에는 glibc malloc의 구현을 살펴봅시다.
(아래 자료는 https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/ 에서 가져왔으며 glibc malloc을 아주 자세히 풀어둔 좋은 자료입니다.)

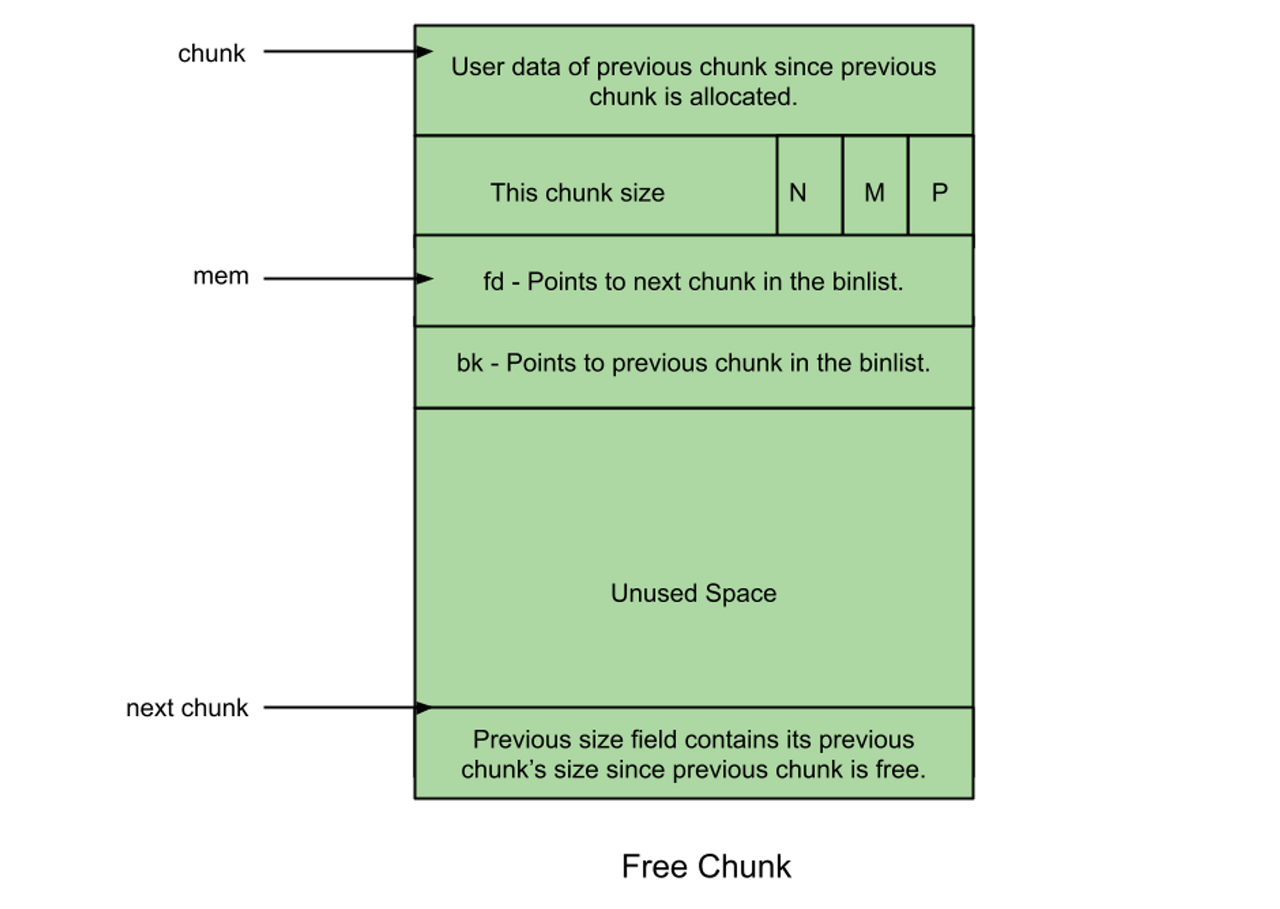
glibc의 경우 할당된 상태와 할당 해제된의 상태에서 서로 다른 구조를 가지고 있습니다. 모든 chunk 앞에는 해당 chunk 대한 정보를 담고 있는 8byte (4byte in 32bit) 정도의 공통된 공간이 존재합니다. 공통된 정보로 chunk size / FLAGS(3bit) 를 담고 있어, 해당 정보를 조회하면 해당 chunk에 대한 정보를 바로 알 수 있습니다.
allocated chunk, 즉, 유저가 사용중인 chunk의 경우 free가 될 때 단순히 이 chunk가 할당된 것인지, 이전 chunk가 사용 중인지, thread 에 관련된 chunk인지 그리고 그 chunk의 사이즈가 얼마인지 정도의 정보만 필요하기에 단 8바이트로 이 모든 정보를 담아낼 수 있습니다.
반면, free chunk 의 경우에는 해당 chunk를 추적해야할 필요가 있습니다. glibc malloc의 경우 free chunk 를 bin 이라는 곳에 따로 넣어서 관리를 하게 되는데, 이 bin 에서 알맞는 사이즈의 chunk를 찾기 위해서 탐색을 해야합니다. 이는 연결 리스트로 구현되어 있기에, 해당 free chunk 의 앞 뒤 chunk를 나타내는 포인터를 담아 해결합니다. (jemalloc의 경우에는 이런 chunk들의 정보를 관리하기 위해서 bitmap, linked list, btree 등 다양한 자료 구조를 사용하기도 합니다.)
그런데, 이 정보의 크기가 실제로 쓸 수 있는 데이터 사이즈보다 너무 클 경우 메모리 공간 효율성이 떨어집니다. 예를 들어, 8바이트를 할당하는데, 24바이트의 공간이 필요해서 정렬까지 총 32바이트의 블록을 할당하는 경우가 발생할 수 있습니다. 그래서 glibc malloc의 경우에 아주 작은 크기의 chunk에 대해서는 fd 포인터만 관리하여 그 크기를 최소화하기도 합니다.
free list
pool과 metadata를 다루는 부분에서 ‘free block 들을 별도로 관리해야한다.’ 하는 이야기를 했습니다. malloc의 경우 논리적인 블록들을 효과적으로 할당해야하기 때문에, 가용한 메모리 블록들을 별도로 관리하게 됩니다. 실제로 pool 이 구성되며 메모리가 할당되고 나면, 이 공간을 논리적 블록으로 만들어 별도의 free list에 저장을 하게 됩니다. 이 free list를 탐색함으로써 malloc은 빠르게 가용한 공간을 찾을 수 있습니다.
glibc malloc의 경우 이 free list를 fastbin, small bin, large bin, unsorted bin 으로 단계적으로 관리하여 필요한 메모리를 빠르게 할당 및 반환을 수행합니다.
multithread
멀티코어의 세상이 오면서, malloc 성능 개선에는 새로운 요구사항이 추가되었습니다. 바로 멀티스레드 상황에서 보다 더 안정적이고 빠른 메모리 할당을 하는 것입니다. 현대의 malloc은 대부분 thread-safe하고 멀티스레드 상황에서도 속도가 저하되지 않도록 설계되었습니다.
우선 thread-safe 해야하는 이유에 대해서 생각해봅시다. 단순히 mmap()을 통해서 할당이 일어나고, free가 된다면 시스템콜이 thread-safe하면 해결될 것입니다. 그러나, 우리가 사용하는 malloc은 pool을 사용합니다. 만약 여러 스레드가 동시에 같은 크기를 할당 요구한다면, 해당 크기에 맞는 free block에 대해서 race condition 이 나고, 문제가 발생할 수 있을 것입니다.
결국 이런 문제를 해결하기 위해서는 공유되고 있는 공간에 대해서 제어하기 위해서 lock이 필요해집니다. 이런 이유로 멀티 스레딩이 등장하고 초기의 malloc의 경우, 단순히 malloc을 할 때 공유자원에 대해 접근/변경을 하는 경우 lock을 모두 걸어버리는 형식을 취했습니다. 그러나, 잦은 lock 경합으로 인해 멀티스레드 환경에서 이러한 방식의 성능이 저하되었고, 이에 따라 멀티스레드 환경에서도 최적화된 malloc 구현이 필요하게 되었습니다.
thread cache
앞서, 우리는 malloc에서 pool이라는 객체를 통해서 미리 할당받은 메모리 공간에 대해서 빠르게 유저에게 메모리를 할당할 수 있다는 것을 알게 되었습니다. 그러나, 이러한 pool은 멀티스레드 환경에서 공유 자원이 되기 때문에 문제가 될 수 있습니다. 만약 모든 스레드가 하나의 공유 pool에 동시에 접근한다면, 수많은 경합 현상이 발생하게 될 것입니다. 때문에, 스레드별로 최소한의 경합이 일어나도록 하기 위해서 ‘thread cache’ 라는 개념을 도입합니다. 이 ‘thread cache’ 또한 구현마다 다르겠지만, 각 스레드마다의 각자의 작은 풀이 존재하는 형태라고 생각하면 됩니다. 각 스레드는 가장 빠르게 자원을 획득할 수 있는 방법으로 우선 thread cache를 먼저 찾아봅니다. 이 경우, lock을 최소화하고 자원을 획득할 수 있기에, 싱글스레드 환경에서만큼 빠르게 메모리를 획득할 수 있습니다.
그런데, thread cache를 도입하면서 또 다른 문제가 발생할 수 있습니다. thread cache는 해당 스레드에 할당된 자원입니다. 만약, 어디선가 할당된 메모리를 그와 다른 스레드에서 해제하는 상황에 놓이게 된다면, 이에 대한 관리가 반드시 필요합니다. 일부 구현에서는 이러한 경우 처리를 하지 못하는 경우도 있습니다. 따라서 특정 스레드에서 할당된 메모리는 해당 스레드가 관리하는 것이 가장 바람직하며, 이는 프로그램의 안정성을 높이는 한 방법입니다.
그러나, 대부분의 경우 멀티스레드 프로그램을 작성하면서 이러한 문제를 직면하지 않았을 것입니다. 이는 glibc malloc 등 일부 구현에서 이러한 상황을 처리할 수 있기 때문입니다. arena에 대해서 한번 살펴봅시다.
arena
arena는 멀티스레드 환경에서 메모리 할당과 해제에 대한 경합을 최소화하기 위해 설계되었습니다. 스레드 수에 따라 여러 개의 arena가 만들어져, 각 스레드가 서로 다른 arena를 사용하면서 경합을 최소화합니다. arena의 크기가 너무 커지면 오버헤드도 증가하기 때문에, 코어수 * 8 과 같이 일정 수의 arena로 제한하고, round robin 방식으로 각 스레드에게 arena를 할당하기도 합니다.
각 arena의 내부에는 미리 할당된 메모리가 존재합니다. 유저가 아무것도 할당 요청하지 않은 상태에서는 이 메모리 블록들은 처음에 arena에 존재합니다. 이후, arena와 관계된 특정 스레드가 할당 요청을 하면 해당 블록은 thread cache로 이동하여 해당 스레드가 보다 더 빠르게 메모리를 반환받고 해제할 수 있도록 합니다.
만약, thread cache에서 원하는 메모리 블록을 찾을 수 없다면, 다시 lock을 걸고 상위 레벨인 arena를 봅니다. arena에 원하는 블록이 있다면 해당 블록을 가져오고, 없다면 arena가 가지고 있는 메모리를 확장합니다. 이렇게 다중 아레나 / 스레드별 캐시 구조로 레벨을 나누었기에 1차적으로 lock이 없이 메모리를 반환받을 수 있으며, lock을 걸더라도 더 적은 스레드간의 경합을 거쳐 메모리를 획득할 수 있습니다.
이제 우리는 malloc이 어떤 방식으로 빠르고 효율적으로 메모리를 반환하는지 알게 되었습니다. 그런데 malloc의 이런 설계에 대해서 조금 더 깊게 이해하기 위해서는 운영체제가 어떻게 메모리를 관리하는지, 그리고 하드웨어적으로 어떻게 흐름이 이어지는지에 대해서 이해해야합니다. 이제 OS과 하드웨어의 세계로 잠깐 들어가봅시다.
하드웨어 최적화
OS 에서 제공하는 메모리 주소는 물리적 메모리 공간의 실제 주소와 같지 않습니다. OS 에서는 프로세스마다 가상 메모리 주소 공간을 제공하고, 시스템에 메모리를 요청하더라도, 이와 관련된 메모리 주소를 mmap() 과 같은 시스템 콜이 제공하기 때문입니다 하드웨어 그리고 OS 단에서 보다 효율적인 malloc 을 작성하기 위해서는 가상 메모리와 메모리 접근 시 일어나는 일들에 대한 이해가 필요합니다.
가상 메모리와 캐시
현대의 OS는 가상 메모리를 통해 메모리 공간을 관리합니다. 한정된 자원인 물리적 메모리를 보다 효율적으로 관리하기 위함입니다. 예를 들어, 32 bit 시스템에서 4GB 의 메모리만 존재함에도 여러 프로세스가 각각 최대 4 GB 의 주소 공간을 할당 받을 수 있는 것도 이 덕택입니다.
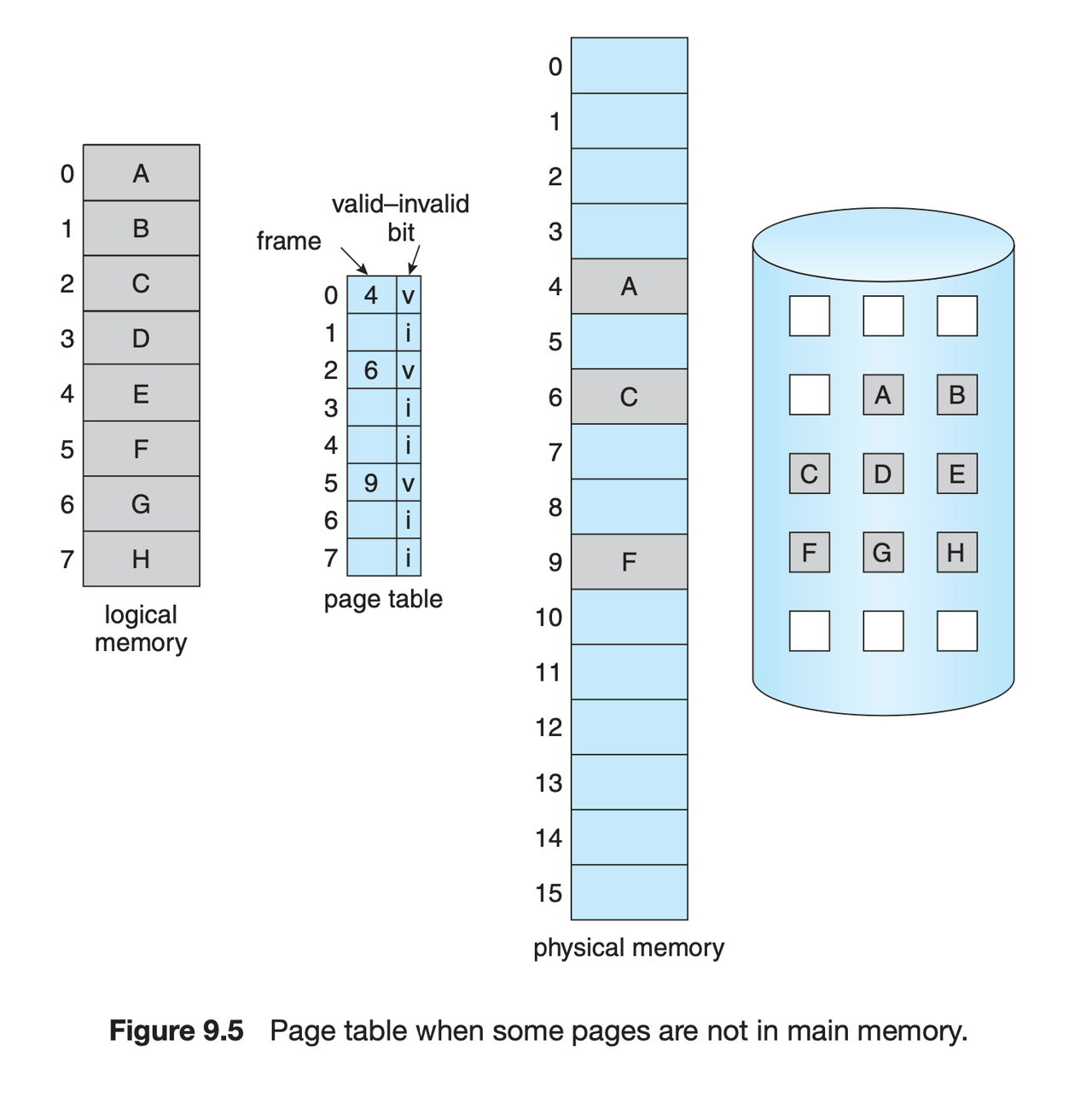
현대 OS에서는 가상 메모리 구현을 위해 대부분 page 를 활용합니다. page 는 물리적 메모리 공간과 가상 메모리 공간과 매핑되어 있는 하나의 논리적 블록입니다. 간략하게 요약하자면, 물리적 메모리를 특정 크기의 블록인 frame 으로 나누고, page 에서는 매핑된 frame 에 대한 정보를 기록하여 물리적 메모리에 접근할 수 있도록 합니다. 또한 메모리가 부족할 경우 2차 저장 공간(disk) 로 이전하여 보관하고(swap-out), 연결된 page 에 대해서 더 이상 유효하지 않음을 표시합니다. (페이징에 관련하여 더 자세한 내용이 있지만, 해당 글에서는 이 정도의 내용으로 축약하겠습니다.)
따라서, 프로세스에서 특정 메모리에 접근을 할 때는 실제 물리적 메모리 주소를 찾기 위한 과정이 필요합니다. 단순하게 생각하면 다음과 같이 일어날 수 있을 것입니다.
- 메모리 접근 요청
- Page table (메모리에 존재) 을 탐색하여 가상 메모리 주소를 실제 메모리 주소로 변환
- 만약, swap-out 되었을 경우 다시 disk 에서 불러들이고 swap-in 된 메모리 주소 제공
- 이는 아주 느린 작업이다.
- 만약, swap-out 되었을 경우 다시 disk 에서 불러들이고 swap-in 된 메모리 주소 제공
이 과정을 위해서는 메모리에 위치한 page table 에 접근하여 주소를 변환하여야합니다. 그러나, 메모리로 접근하는 행위는 CPU 에 위치한 cache 를 사용하는 것보다 수 배에서 수 십배 더 느립니다.

이러한 문제를 해결하기 위해서 CPU 의 MMU 에서는 translation lookaside buffer(TLB) 를 통해서 메모리 주소를 빠르게 처리하도록 설계되었습니다. 하지만, TLB 또한 한정된 공간을 사용하고 있기 때문에, 최근에 사용하지 않은 Page 라면 해당 정보를 가지고 있지 않고, Page table 을 뒤져보며 주소를 변환해야합니다.
앞서, 물리적 메모리 접근은 상당히 느리다는 사실을 알게되었습니다. 실제 메모리 주소를 TLB를 통해서 찾았더라도, 실제 메모리로 다시 접근을 해야한다면 여전히 느린 작업이 될 것입니다. 이러한 오버헤드를 줄이기 위해, CPU에서는 캐시 메모리를 가지고 있습니다. 캐시 메모리는 아주 빠른 접근 속도를 보장하지만, RAM 에 비해 턱없이 적은 용량을 가지고 있습니다.
이러한 이점을 누리기 위해 최근 사용한 메모리의 경우 RAM에 바로 기록하지 않고 캐시 메모리에 기록을 하는 전략을 취합니다. (프로그램의 사용 패턴을 고려할 때, 메모리는 공간적, 시간적으로 지역성을 보입니다. 이를 생각할 때, 합리적인 선택입니다.) 이후 다시 해당 메모리에 접근할 때는 RAM 까지 도달하지 않고 캐시 메모리에 접근하여 보다 빠르게 메모리의 정보에 접근할 수 있습니다.
그러면 다시 메모리 접근 과정을 살펴봅시다.
- 메모리 접근
- MMU에서 주소 변환A. TLB 에서 해당 페이지를 찾을 수 있는가?
- HIT
- 물리적 주소로 변환
- Cache에 해당 메모리에 대한 정보가 있는가?
- HIT (Fastest)
- Cache 에서 정보 획득
- MISS
- RAM 으로 접근하여 정보 획득
- HIT (Fastest)
- MISS
- Page table 에서 page 탐색
- 해당 페이지가 RAM에 존재하는가
- YES
- 페이지 테이블 갱신 이후 A로 복귀
- NO (Slowest)
- 보조 기억 장치에서 Swap-in
- 페이지 테이블 갱신 이후 A로 복귀
- YES
- 해당 페이지가 RAM에 존재하는가
- Page table 에서 page 탐색
- HIT
- MMU에서 주소 변환A. TLB 에서 해당 페이지를 찾을 수 있는가?
이를 살펴볼 때, 최대한 TLB, 캐시에 존재하는 메모리 공간에 접근하도록 하는 것이 바람직하다는 것을 알 수 있습니다. 그렇다면 malloc 에서는 어떤 방법을 통해서 이를 최적화할까요?
최적화 예시
malloc 을 하드웨어 친화적으로 최적화하는 핵심은 “캐시를 활용하라” 입니다. 그런데 어떻게 해야 캐시를 잘 활용할 수 있을까요? 일반적으로 malloc은 다음과 같은 전략을 취합니다.
- 최근에 free 된 block을 우선으로 제공하기
시간적 지역성을 활용하는 방법으로, 최근에 사용한 블록을 다시 제공하여 캐시를 활용하게 하는 것입니다. 최근 free 된 공간의 경우 최근 메모리에 접근되어 cache에 존재할 가능성이 높습니다. 따라서, 사용자에게 해당 메모리 공간을 제공하면 cache 에서 메모리 접근이 가능하다는 이득을 취할 수 있습니다. 하나의 예시로 free list 의 head 에 최근 free 된 block 을 넣고, 다시 할당 요청이 왔을 때 해당 block 을 제공하는 방법을 사용할 수 있습니다.
- 블록이 하나의 페이지에만 위치하도록하여 제공하기
공간적 지역성을 활용하는 방법입니다. 예를들어 다음과 같은 상황을 생각해봅시다. 512 byte 의 메모리 공간을 요청했을 때, 할당 받은 block 이 페이지의 경계에 걸쳐있는 상황입니다.
char *s = malloc(512);
============================== s memory =========================
0 32 64 96 128 160 192 224 256 288 320 352 384 416 448 480 512
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| PAGE A | PAGE B |
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
==================================================================
s[0] ~ s[255] 까지의 접근의 경우 PAGE A 에 대한 접근인 반면, s[256] ~ s[511] 까지의 접근의 경우 PAGE B 까지의 접근입니다. 만약 A 의 경우 캐싱이 되어있고 B 의 경우 캐싱이 되어있지 않다면, 같은 블록 내에서의 메모리 접근에 대한 시간이 차이나게 됩니다. (높은 확률로 같은 블록의 메모리에 접근할 것임에도 불구하고 말입니다.) 따라서, 블록을 자를 때 페이지를 넘기지 않도록 하여 제공한다면, 사용자 입장에서는 같은 메모리 블록을 사용할 때 캐시를 통해 보다 더 빠르게 접근할 수 있습니다.
- Aligned 된 메모리 제공하기
CPU의 동작, 그리고 cache line 과 관련이 있습니다. CPU의 경우 메모리를 읽어들일 때 정렬된 메모리로 가정하고, 메모리에 접근합니다. 만약 정렬되지 않은 주소로 접근을 하게 된다면, 성능면에서 손실을 입을 수 있습니다. 예를 들자면 32비트 기반 시스템에서 0x01 에 위치한 8 바이트의 메모리 접근을 요구하면 0x00 과 0x08 에 대한 두 번의 메모리 접근이 필요할 수도 있습니다. 또한 Cache 에서 또한, 정렬된 주소를 바탕으로 저장하여, 두 번의 cache 접근이 발생하는 문제가 발생할 수 있습니다. 따라서, memory 를 32 비트 환경에서는 4 바이트, 64 비트 환경에서는 8바이트의 배수로 align 하여 이러한 문제가 발생하지 않도록 할 수 있습니다.
malloc의 실제 구현에서는 앞서 보여드린 것처럼 멀티 스레드 상황을 대비하여 lock contention을 낮추기 위해 arena, thread cache를 도입한다거나, 보다 효과적인 branch 예측을 위해 __builting_expect 와 같은 컴파일러 내장 함수를 사용하여 내부 분기 예측을 최적화하기도 합니다.
글을 마치며
malloc 에 대한 대장정이 드디어 끝났습니다. 많은 내용을 살펴본 것 같지만, malloc 에 대해 다룰 내용은 더 많습니다. 각 malloc 의 구현마다 다양한 자료구조를 통해 내부 동작 속도를 끌어올리기도 하고, 여기서는 언급되지 않은 다양한 최적화 전략, malloc 디버깅을 위한 환경 변수와 관련된 툴 또한 존재합니다. 관련된 OS, 하드웨어 단에서의 지식 또한 이 글에서는 아주 짧게 정리되어있지만, 배울 것이 더 넘쳐납니다.
개인적으로는 큰 의미를 두지 않고 시작했던 프로젝트였는데 생각보다 구현 기간도 길어지고 배움의 깊이도 더 깊게 들어가게 되었던 과제였습니다. 쉽지는 않은 여정이었지만, 해당 과제를 통해서 OS 와 하드웨어에서 메모리를 다루는 방식에 대해서 더 깊게 알게 되었습니다. 여기까지 글을 읽으신 다른 분들도 각자의 malloc을 만들어보시는 것은 어떨까요? ㅎㅎ..
그리고. 제 malloc 이 궁금하신 분은 아래 github 에서 구경해보세요 🙂
 JuneParkCode
JuneParkCode

