홈 서버 모니터링 시스템 Oracle Cloud 로 이전하기 (1)
서버가 터졌는데 4시간 후에야 알았다..! 클라우드로 모니터링 서버를 옮겨보자.

배경
- 아찔한 일이 있었다. 면접을 보는 당일에 갑작스레 집에 있는 서버가 다운이 되었다. 이를 인지한 것은 실제로 서버가 다운되고 4시간이나 지난 이후였다. 다행히 면접 과정에서 직접 서버에 접속하거나 하는 일은 없었지만, 완전히 손을 댈 수 없는 상황이 되어 상당히 당황스러웠다.
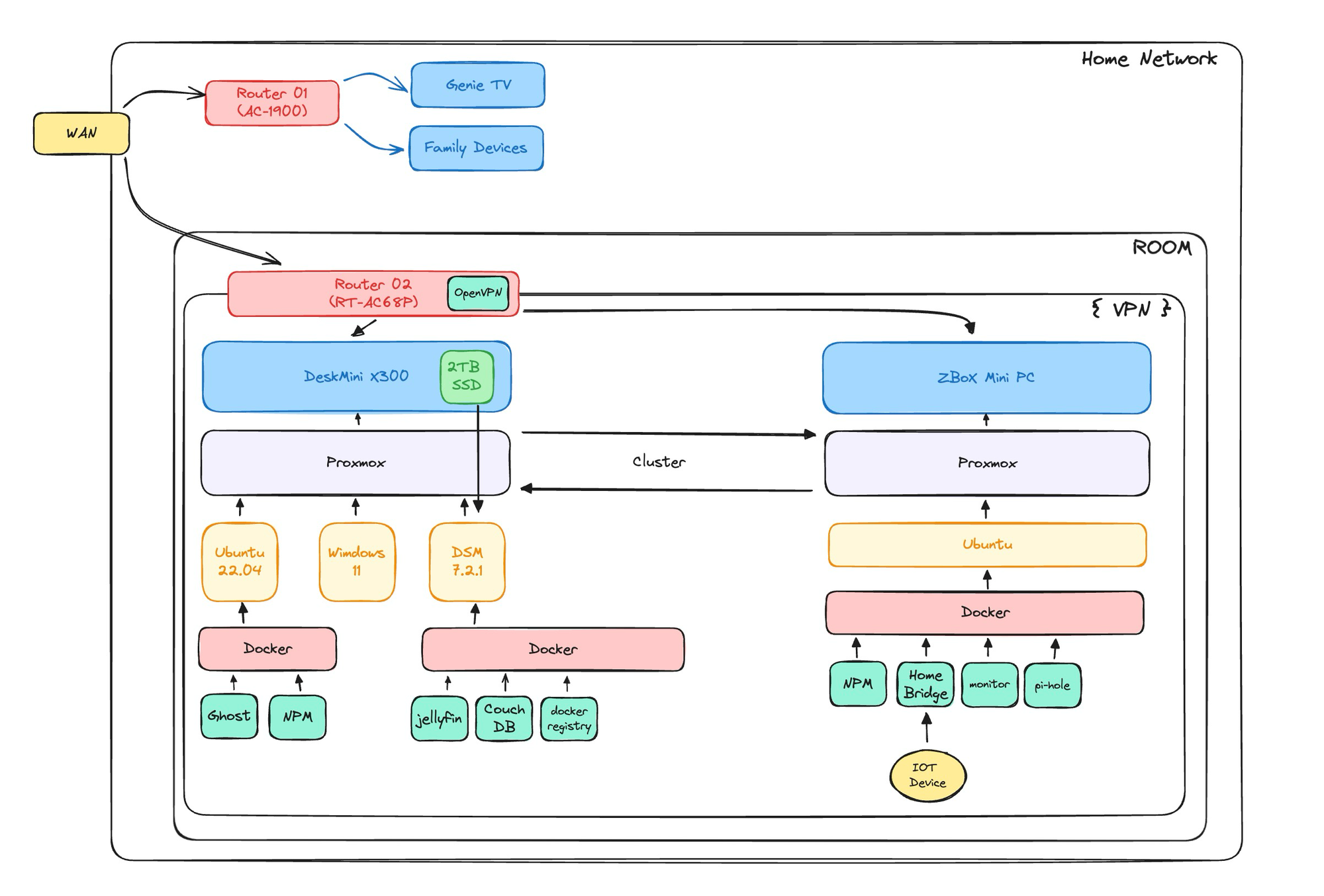
- 기존 서버의 경우 위와 같은 구조를 취하고 있는데, 내부망 관리 및 모니터링과 실제 서비스 파트를 나누고 있을 뿐이다.
- 현재 상태에서는 여러가지 문제 상황이 발생할 수 있다.
- 서비스 서버가 뻗는 경우
- 서비스 접속 불능으로 이어짐.
- 해당 경우에는 서버가 다운 된 것을 인지하기만 하면, 원격으로 재부팅 / 재설정이 가능하다.
- 모니터링 서버가 뻗는 경우
- 모니터링이 중단되고, 내부 DNS 서버가 중지되어 내부 망 접속에서 문제가 발생할 수 있음.
- 라우터가 다운되지 않았다는 가정 하에, 재부팅 및 재설정은 가능함.
- 서버 라우터, 혹은 WAN 이 들어오는 첫 모뎀쪽 스위치가 다운되는 경우
- 이 케이스로 인해서 이번에 서버가 완전히 접속 불가하였음.
- 외부에서 접속할 수단이 아예 존재하지 않으므로, 원격으로 처리할 수 있는 방안이 존재하지 않음.
- 적어도 서비스가 중단되었다는 사실은 인지할 필요가 있음.
- 서비스 서버가 뻗는 경우
해결 방안 모색
- 이번에 발생한 문제는 "외부에서 완전히 대응이 불가능한" 상황이었다.
- 이상적으로는 외부에 다른 클러스터를 구축하고 이중화를 함으로서 해결하는 방법이 있다. 그러나 비용을 생각하면 합리적이지 않다.
- Proxmox Cluster 로 추가 구성하는 경우에는 서버 구축 비용이 추가로 발생한다. 한 두푼이 아니라서 제외한다.
- 클라우드의 무료 서비스를 활용해보는 것도 고려해보자.
- 완전히 서버가 다운이 되는 경우에 대해서는 대응은 하지 못하더라도 적어도 서버가 다운되었다는 사실은 인지해야한다. 따라서, 각 서버에 대해서 health check 를 외부에서 할 수 있도록 하고, 문제가 발생한 경우 알림을 받을 수 있도록 하려고 한다.
- 안정성이 최우선이므로, 이는 외부 클라우드를 통하는 것이 적절하다.
- 가능하다면, 이중화도 고려해본다.
클라우드 선정
- 클라우드 선정에서 가장 중요한 것은 비용이다.
- 성능의 경우 관리하는 서버가 많지 않고 고부하 작업이 존재하지 않기에 크게 고려하지 않는다.
클라우드(Cloud) 프리티어 비교 - 서비스 및 스펙 비교 - 상시 무료 비교
클라우드 프리티어 이번에는 각 4개 회사의 클라우드 프리티어 서비스 중 기본인 컴퓨트(VM) 스펙 중점으로 비교 확인 해보도록 하겠습니다. 클라우드 회사에서는 여러가지 유형으로 맛보기 서비스 형태인 프리티어 서비스 를 하고 있습니다. 프리티어 제공 내역 프리티어 안에는 세부적으로 크게 상시 무료 와 기간제 무료 그리고 크레딧 제공 형태로 구분 됩니다. - 기간제 무료는 특정 기간에서
 Jade(정현호)
Jade(정현호)- 다른 Cloud VM 프리티어의 경우 대부분 기간의 제한이 있다.
- 러닝커브를 생각하면, 기존에 사용할 수 있던 AWS 를 사용하는 것이 좋을 수 있다만 1년의 프리티어 제한을 이미 다 써먹었다. (계정을 새로 만들면 되기는 함)
- 오라클의 경우에는 ARM 을 사용하는 VM 의 경우 무료로 사용이 가능하다.
- 꽤 매력적인 조건이다.
- ARM 4 core / 24GB or 1GB / 6GB *4 VM 이 가능하다.
- Oracle DB (10GB 정도) 사용이 가능하다.
- Object Storage 10GB 도 사용이 가능하다.
- 가장 놀라운건 "평생 무료" 라는 점이다.
- 언젠가는 막힐지도 모르겠지만...?
오라클 클라우드 삽질기
Free-tier VM Instance 만들기
- 이게 삽질이 될 줄은 몰랐다...
- 오라클 클라우드는 프리티어를 제공하기는 하나, 이 사용량이 제한되어있다.
- 이 소식을 듣고 다른 홈 리전(싱가폴)에 지정하여 만들었다. 그러나 싱가폴 리전도 포화 상태이다. 괜히 쓸데없이 먼 곳에 동록했다(...) 더군다나 오라클 클라우드의 경우 계정 재생성이 어렵다.
- 새로 계정을 파더라도 기존에 사용한 카드 번호를 사용할 경우 계정 블락이 되거나 아예 생성이 되지 않을 수 있다. (AWS 가 벌써 그리워진다.)
- 모니터링용으로 구성하는 서버이기에 우선은 신경을 끄도록 하려고 한다. 실제 서비스를 올리는 경우는 아직 없고, 있더라도 이중화 목적으로 사용할 것이다.
- 이 소식을 듣고 다른 홈 리전(싱가폴)에 지정하여 만들었다. 그러나 싱가폴 리전도 포화 상태이다. 괜히 쓸데없이 먼 곳에 동록했다(...) 더군다나 오라클 클라우드의 경우 계정 재생성이 어렵다.
- 프리티어 계정에서만 생성이 되지 않는 것이기 때문에 유료 계정으로 전환했다
- 지급 검사로 100불 정도 소요가 되었다.
- 일반적으로 이것도 바로바로 취소되는 편인데, 왠걸 바로 취소가 되지 않아 당황했다. (아직도 안됐다...)
- 카드 결제 뿐 만아니라, 계정 업그레이드도 시간이 소요된다. (돈 주고 쓴다는데 대체 왜 이러는지 이해할 수가 없다.)
- 계정 업그레이드는 빠르면 30분 길면 일주일 정도 소요된다. 나는 약 3시간 정도의 시간이 소요됐다.
- 유료 계정으로 전환한 뒤, 정상적으로 인스턴스를 생성할 수 있었다. 우선 만든 인스턴스는 ARM 2 core / 12G RAM 이다.
- SSH 접속의 경우, 첫 생성 과정에서 얻은 private key를 통해 접속할 수 있었다.
- 이후 고정 IP 할당을 해줬다.
- Reserved IP 설정 업데이트가 바로 되지 않는데, 기다리면 된다.
[OCI] 오라클 클라우드 - 2. 고정 IP 설정
오라클 클라우드에 VM을 생성하면 임시 IP가 배정이 되는데 외부에서 접근하기 위해서는 고정IP를 설정해 주어야 한다 1. 고정IP 예약 설정 OCI에서 먼저 고정IP를 예약하자 아래와 같이 OCI 메뉴에서 Networking → IP Management → Reserved Public IPs 로 접속한후 Reserve Public IP Address 버튼을 눌러 고정 IP를 예약하자 Reserve Publlic IP Address 메뉴로 들어가면 아래와 같은 창이 나오는데 Reserved Public IP Address Name 에 임의의 이름을 입력하고, IP Address Source에서 Oracle을 선택한 후 아래쪽에 Reserve Public IP Address 버튼을 클릭하면 아래와 같이 위…
 기억력이 점점 나빠진다
기억력이 점점 나빠진다
기본 설정
- 초기에는 사용자가 ubuntu 로 지정되어있다. 보안적인 이유로 계정명을 변경했다.
오라클 클라우드 우분투 계정 설정 가이드 - 이불색 하늘
계정 이름을 생성 전 정할 수 있는 Azure와 달리 오라클, AWS (필자는 AWS를 사용해보지 않았지만) 등에서는 가상 컴퓨트 인스턴스, 그러니까 서버를 생성할때 사용자 이름을 ubuntu로 부여해준다. ssh ubuntu@ip -i ~/.ssh/id_rsa.pub 일단 서버로 ssh접속을 한다. sudo -i 접속 후 루트 계정으로 로그인한다. adduser user를 추가한다. 는 꼭 자신이 하고 싶은 이름으로 바꾸도록 한다. (예: azureuser, ...) mkdir


- 네트워크 inbound / outbound 보안 규칙 설정이 필요하다. VCN (AWS 의 VPC 가 여기서는 VCN 이다.) 에서 보안 규칙을 설정한다.
Oracle Cloud에서 HTTP 포트 열기
Oracle Cloud를 사용해서 웹 서비스를 만들경우 기본적으로 ICMP, SSH만 열어놓기 때문에 HTTP, HTTPS 요청은 거부하게 됩니다. 이를 해결하기 위해서 Oracle cloud에서 HTTP, HTTPS를 제공하기 위해 해당 포트를 여는 방법을 정리해보겠습니다. 먼저, 오라클 클라우드 콘솔로 접속합니다. 네트워크 관련 설정을 위해 가상 클라우드 네트워크(VCN)로 이동합니다. 현재 인스턴스가 속해있는 VCN을 선택해서 들어갑니다. (따로 설정하지 않았다면 기본으로 생성되어있는 것 한개만 존재합니다.) VCN에 들어가면 좌측에 리소스에 네트워크 보안 그룹으로 이동합니다. 새로운 규칙을 생성하기 위해 ”네트워크 보안 그룹 생성” 버튼을 눌러 새로운 보안 그룹을 생성합니다. 네트워크 보안그룹에…
yongckim
- 조금 더 편리하게 접속을 하고자, 해당 서버에 따로 별칭을 주기로 했다.
photogrammer.me의 DNS 를 관리하는 cloudflare 에서 레코드 테이블에 추가했다.
모니터링 구축
- 모니터링의 대상은 다음과 같다.
- Oracle Cloud VM / 내부 모니터링 서비스
- Router
- Proxmox hosts
- Home server 의 웹 서비스
- 기존의 모니터링의 경우 InfluxDB + Grafana 형태였으나, 이번에는 Prometheus 로 변경하고자한다.
- Promethus 를 사용함으로서 기존 Proxmox 이외에도 Router 쪽의 metric 을 보다 쉽게 가져올 수 있으며, Blackbox exporter 를 활용하면 service health check 도 조금 더 간편해진다.
- 추가로, 전원 사용량 관련해서도 모니터링을 추가할 예정인데 metric 을 prometheus 로 뽑아주는 코드가 있어 간편하다.
- 아무래도 influx db 는 시계열 데이터베이스일 뿐이기 때문에, metric 에 특화된 prometheus 를 활용하는 것이 조금 더 좋겠다.
Oracle Cloud 내부 서비스 모니터링 하기
- 홈 서버와의 통신의 경우 보안적인 문제를 먼저 고려해야한다. Prometheus 를 통해서 통신을 하게 될 것인데, Prometheus 의 경우 pulling 방식으로 데이터를 가져온다. 이는 홈서버에서 pulling 을 하기 위한 포트를 별개로 개방해둬야한다는 의미가 된다.
- 그러나, 어디서나 내 서버의 정보를 가져오도록 하는 것은 바람직하지 않다. 이 부분에 대해서는 잘 생각해서 최대한 타인이 접근할 수 있는 구조로 변경해야한다.
- 이러한 이유로 우선 Oracle cloud 내부의 서비스를 Promethues + Grafana 를 통해서 모니터링하도록 했다.
Grafana
- 모니터링 시각화 도구로서 Grafana를 활용한다.
- 현재 계획은 Grafana 를 시각화 도구로 활용하고, Prometheus 는 metric 수집 도구로 활용하고자 한다.
- docker compose 를 통해서 container 로 올린다.
grafana:
image: grafana/grafana:latest
container_name: grafana
restart: always
ports:
- ?:3000
volumes:
- ./data/grafana:/var/lib/grafana
depends_on:
- prometheus
networks:
- monitoring- 해당 설정에서 Grafana 가
permisson deined를 뿜으며 start 되지 않는 문제가 발생하였다.volume으로 잡은 곳에 grafana 가 접근을 하지 못하고 있었다.- 처음에는
user:root로 권한을 잡아줬으나. log 에서 previliged 된 유저를 사용하는 것에 대해서 경고를 했다. - 따라서,
volume으로 잡은 디렉토리에 대해 권한을 변경했다.sudo chmod 777 {volume_dir}- 다만 조금 더 섬세하게 권한을 제어하는 것이 낫다고 본다.
Prometheus
- 기존 홈서버의 경우 InfluxDB 에 metric 을 push 하고 grafana를 모니터링 시스템으로 활용하고 있었다. 이는 Proxmox 자체에서 InfluxDB 로 metric 을 보내는 기능은 있으나 Prometheus 쪽으로 보내는 기능은 내장하지 않았기 때문이었다.
- 그러나, 이번에는 Prometheus 로 통합해서 모든걸 해보려고 한다. InfluxDB 의 경우 시계열 DB 일 뿐 모니터링에 대한 책임은 없다. 그러나 Prometheus 는 이를 위해 탄생한 프로그램이며, Prometheus 에 metric 을 보낼 수 있는 다양한 서비스들이 존재한다.
- 현재 VM 상태 또한 직접 InfluxDB 쪽으로 보내도록 cron job 을 만들거나 해야하는데, 이보다는 아래 활용한
node-exporter를 활용하는 것이 더 편리하며, 웹 서비스의 상태 체크 또한blackbox exporter를 활용하는 것이 더 편리하다. - 아무튼, Prometheus 또한 docker compose 에 함께 올렸다.
prometheus:
image: prom/prometheus:latest
container_name: prometheus
restart: unless-stopped
volumes:
- ./configs/prometheus.yml:/etc/prometheus/prometheus.yml
- ./data/prometheus:/prometheus
command:
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/prometheus
- --web.console.libraries=/etc/prometheus/console_libraries
- --web.console.templates=/etc/prometheus/consoles
- --web.enable-lifecycle
ports:
- ?:9090
networks:
- monitoring
depends_on:
- node-exporter
- blackbox
- Prometheus 의 경우 metric 수집을 위한 config 가 별도로 필요하다. 설정은 아래와 같이 했다.
- 아직 이쪽 config에 대해서 자세히 알고 있지 않아, 기본적으로 각 exporter 들의 기본 설정을 가져왔다.
global:
scrape_interval: 1m
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 1m
static_configs:
- targets:
- prometheus:9090
- job_name: 'node'
static_configs:
- targets:
- node-exporter:9100
- job_name: blackbox
metrics_path: /probe
scrape_interval: 5s
params:
module: [http_2xx]
static_configs:
- targets:
- ...
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox:9115
Node exporter
- node exporter 는 host 의 상태를 prometheus 로 export 할 수 있도록 돕는 도구이다.
- 이상적으로는 host 쪽에 직접 설치하는 것이 바람직하다. 그러나, 다행히도 container 로 올려서 host 의 정보를 받아올 수 있도록 하는 방법이 존재했다.
- container 의 특성상 host 쪽의 정보를 알게하는게 적절한 행동은 아니다.
- docker compose 는 다음과 같다.
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
restart: unless-stopped
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- --path.procfs=/host/proc
- --path.rootfs=/rootfs
- --path.sysfs=/host/sys
- --collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)- Prometheus 쪽에서도 설정을 잡아줘야한다.
- job_name: 'node'
static_configs:
- targets:
- node-exporter:9100- Grafana 에서 node exporter dashboard 를 가져왔다. 단순하게 prometheus 로 연동하면 끝난다.
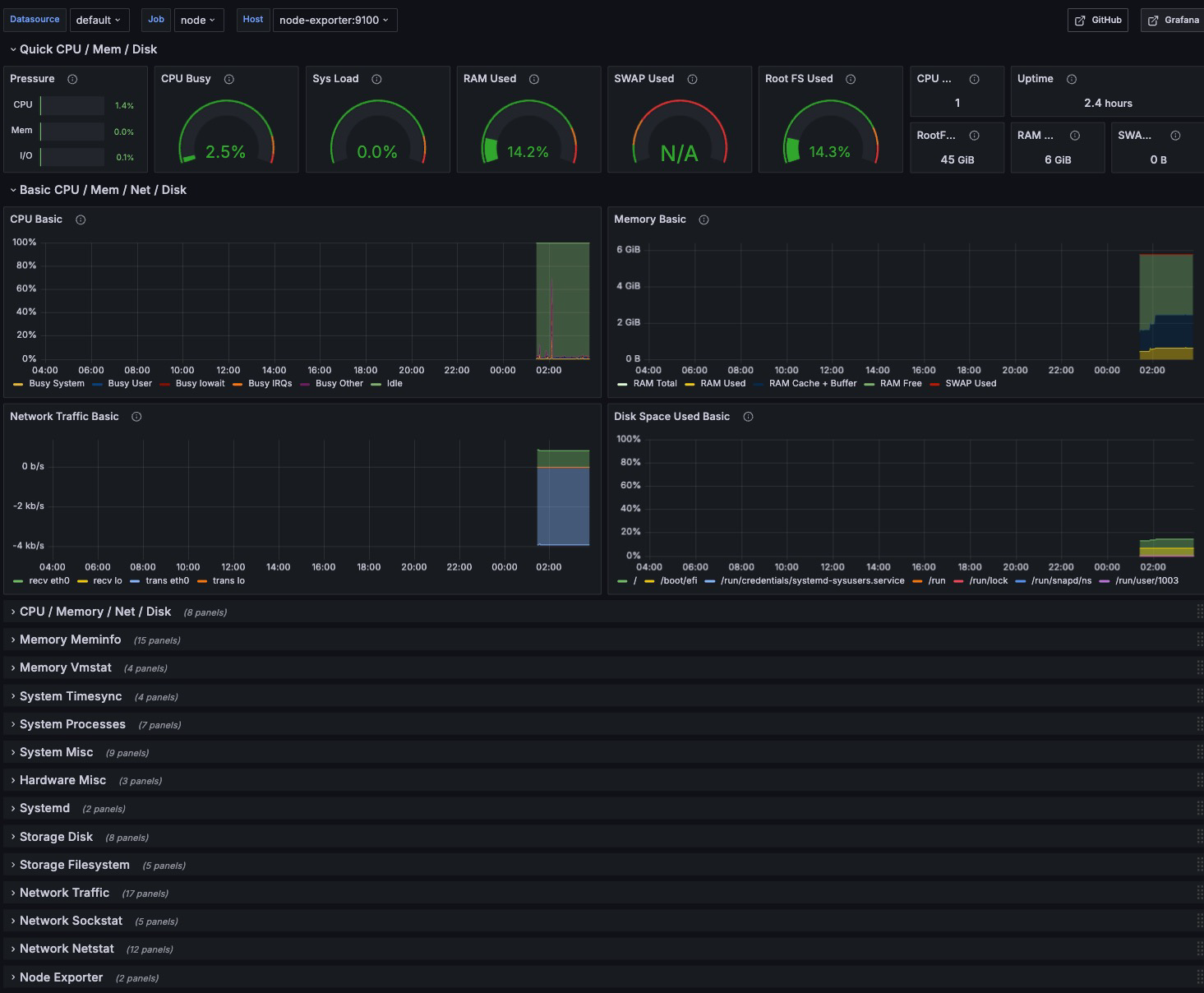
- 연동 과정 중에 docker network 가 서로 제대로 연결이 되지 않아 문제가 발생했었다. 이유는 멍청하게 해당 서비스를 도커 네트워크에 묶지 않았던것, 그리고 네트워크 내부 망인데 외부 포트로 연결하고 있던 것이었다.
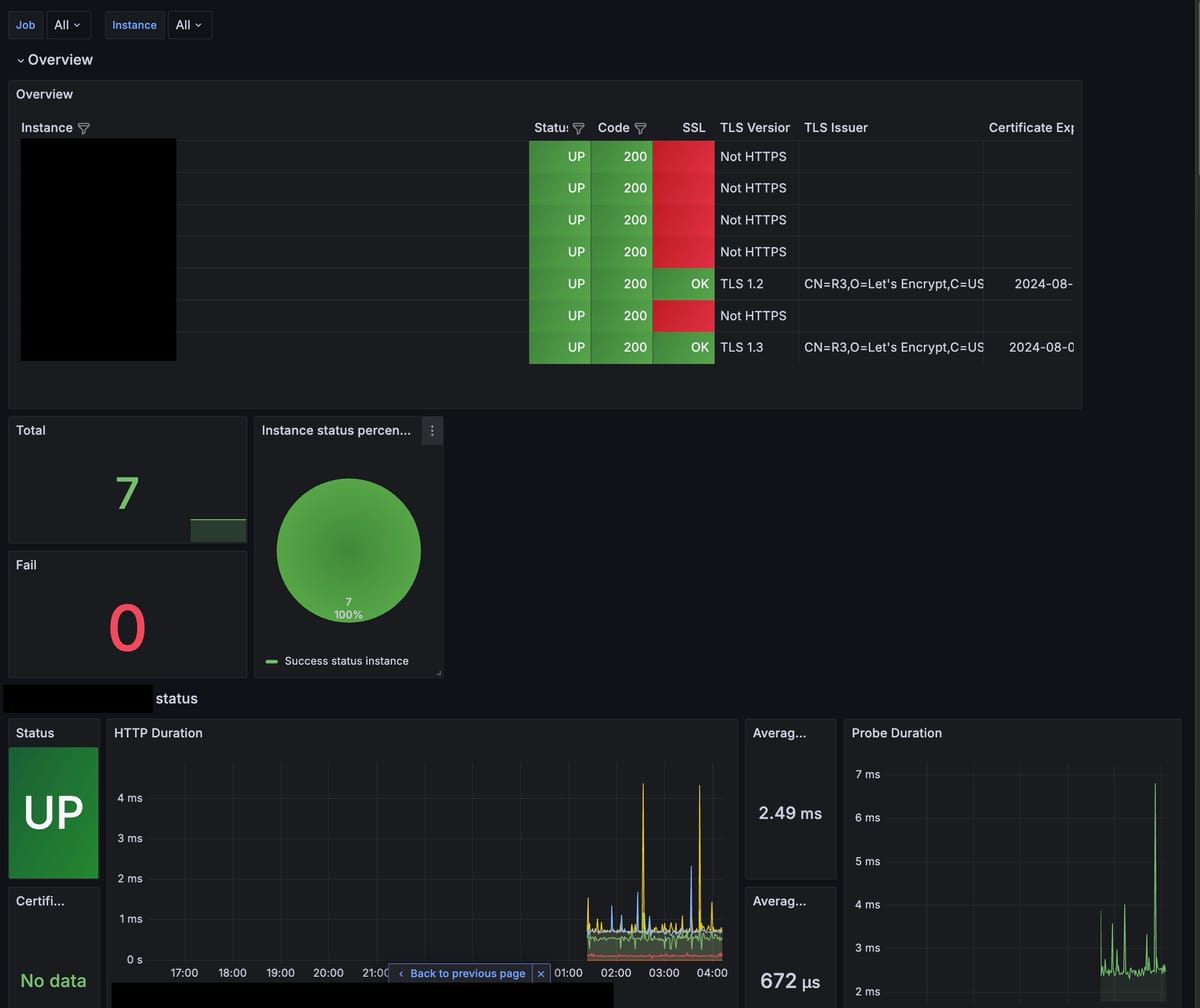
Blackbox exporter
- blackbox exporter 는 Web service 들에 대해서 healthcheck 를 하고 이에 대한 metric 을 export 하는 툴이다.
- 이번 모니터링 도구의 핵심이며, 홈에서 호스팅하고 있는 서비스에 대해서 모두 모니터링 할 것이다.
- 설치 및 설정은 간단하다. 아래와 같이 compose, blackbox config, prometheus config 를 작성했다.
- docker compose
blackbox:
image: prom/blackbox-exporter:latest
container_name: blackbox
ports:
- 19115:9115
command:
- --config.file=/etc/blackbox/blackbox.yml
volumes:
- ./configs/blackbox.yml:/etc/blackbox/blackbox.yml
networks:
- monitoring
restart: unless-stopped
- blackbox config
modules:
http_2xx:
prober: http
timeout: 5s
http:
method: GET
- prometheus config
- job_name: blackbox
metrics_path: /probe
scrape_interval: 5s
params:
module: [http_2xx]
static_configs:
- targets:
- ...
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox:9115
- 마찬가지로 Grafana 에 이미 만들어진 dashboard 를 넣어줬다. prometheus 랑 연동하면 끝.
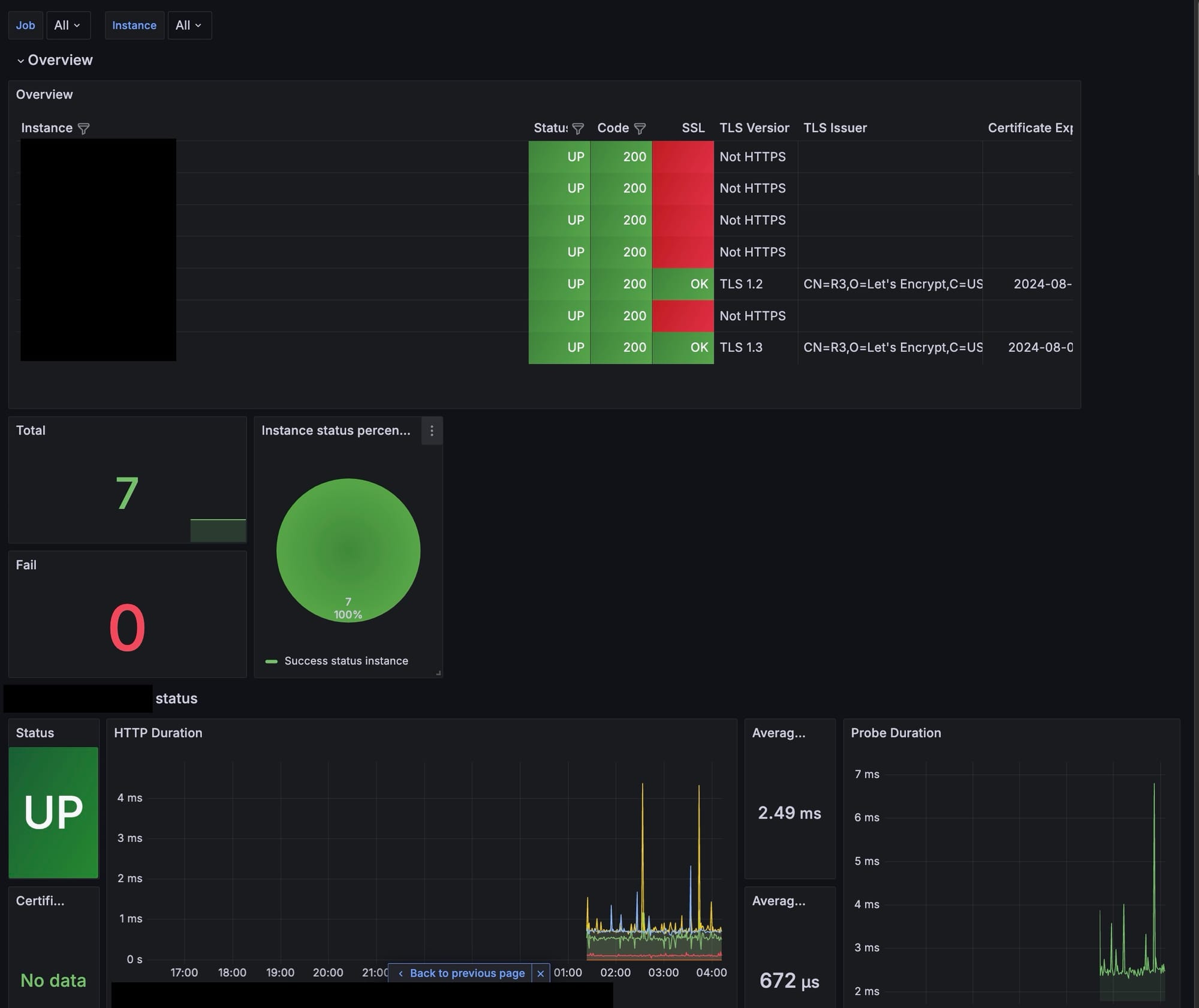
- 추가로, 서비스가 다운 된 경우 알림이 오도록 간단하게 알림을 설정했다.
- Dashboard 에서 Fail 부분에 0 이상 값이 도달한 경우 알림을 송신하도록 설정했다.
- 홈 서버 전체를 내려보았고, 정상적으로 알림을 수신할 수 있었다.
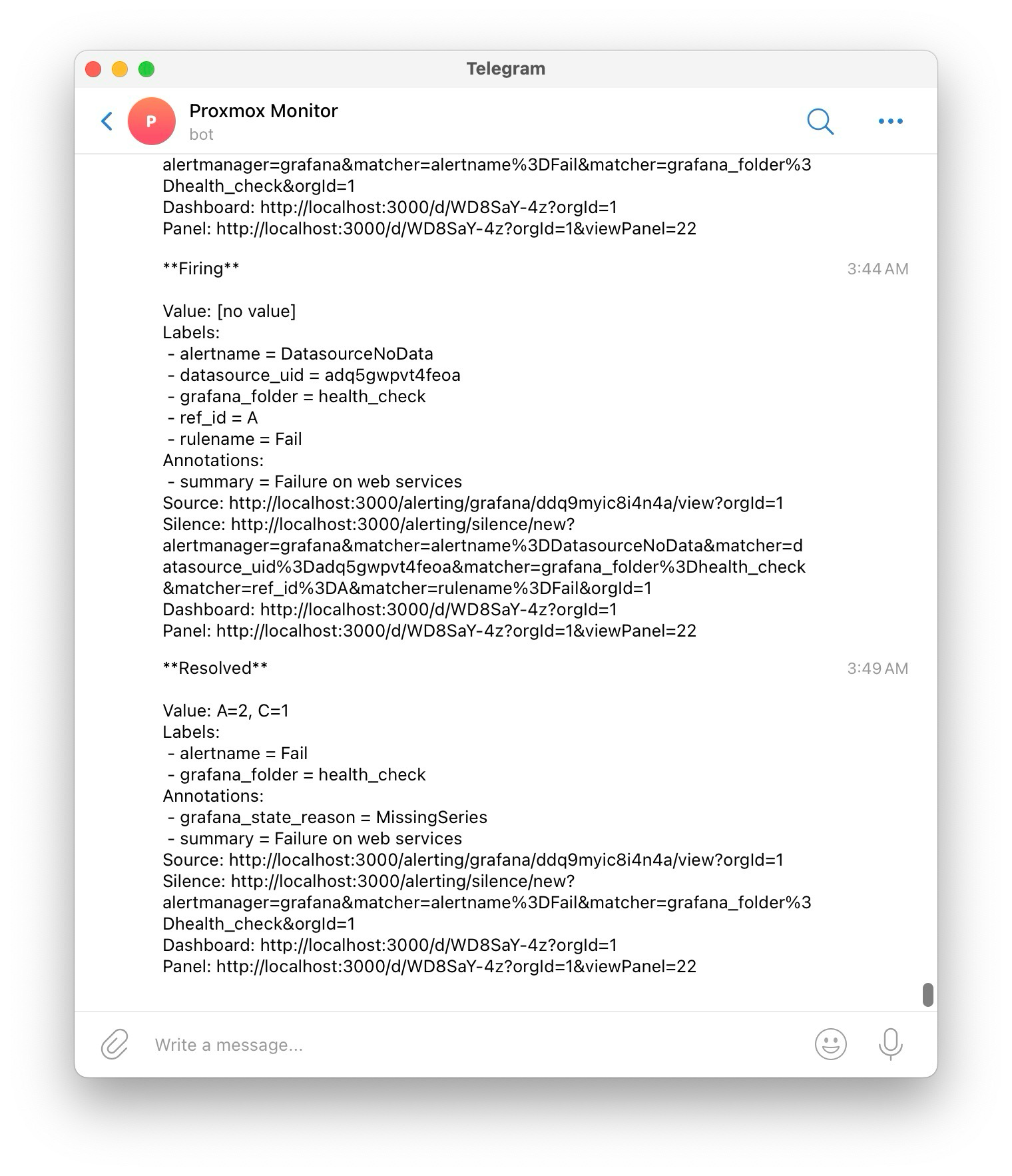
- 이렇게 설정하고 이틀 정도 사용했는데, 거짓 알림이 자꾸만 왔다.
- 기존 alert 의 경우
count(probe_success{ job ~= blackbox} == 0)으로 체크를 하고 있었는데, probe 에 종종 실패하는 경우가 많이 발생하는 것이 문제였다. - 따라서, 특정 지점에서의 값을 보는 것 보다는 일정 interval 에서 비교하는 것이 적합하다고 판단했다.
- 기존의
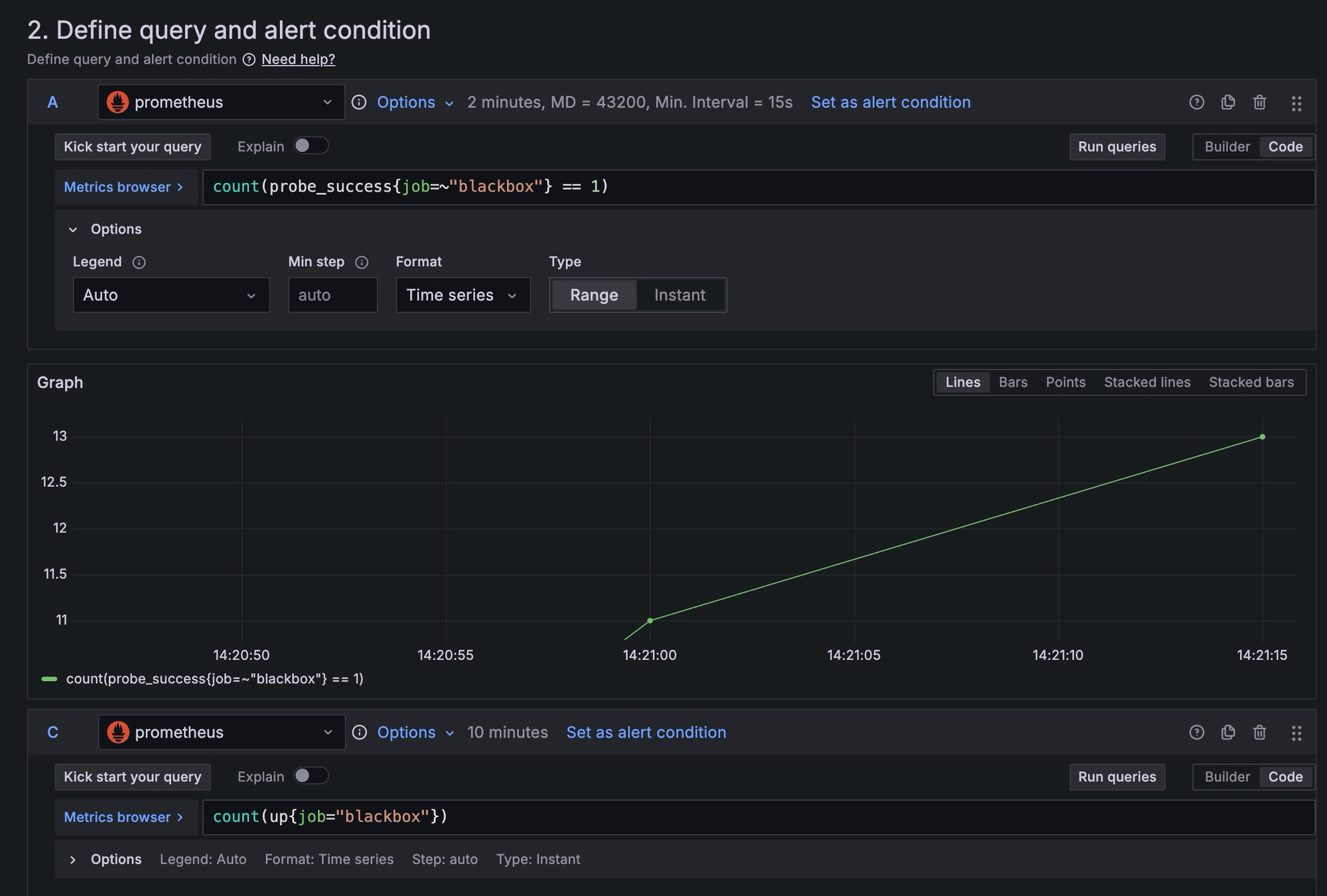
count(probe_success{ job =~ blackbox} == 0)는 probe 에 실패한 갯수를 세는데, 이렇게 하면 일시적으로 probe 에 실패하는 상황에서 거짓 알림 문제가 발생한다. 이 거짓 알림은 순전히 운으로 나오는 것이라서, 재수가 없으면 pending 되는 중에도 다시 probe 에 실패하고 알림을 발송한다. - 따라서, probe 대상의 갯수와 interval 동안 probe 에 성공한 갯수의 최댓값을 비교하도록 했다. 따라서 A 값을 probe 에 성공한 수인
count(probe_success{ job =~ blackbox} == 1)로 수정하고, 이를 2m 동안의 interval 동안의 range 로 가져오도록했다. - probe 대상의 수도 필요하다. 이는
count(up{job=blackbox})로 획득할 수 있다. - A 값은 시리즈이기 때문에, 이 값들 중에서 MAX 값을 reduce 해온다. 인터벌 내내 MAX 값이 up 값과 일치하지 않는다면 특정 서버가 다운되었음을 의미하게 된다.
- 그리고 $B==$C 값으로 해당 true / false 로 표현하고 threshold 를 잡아줬다.
- 기존의
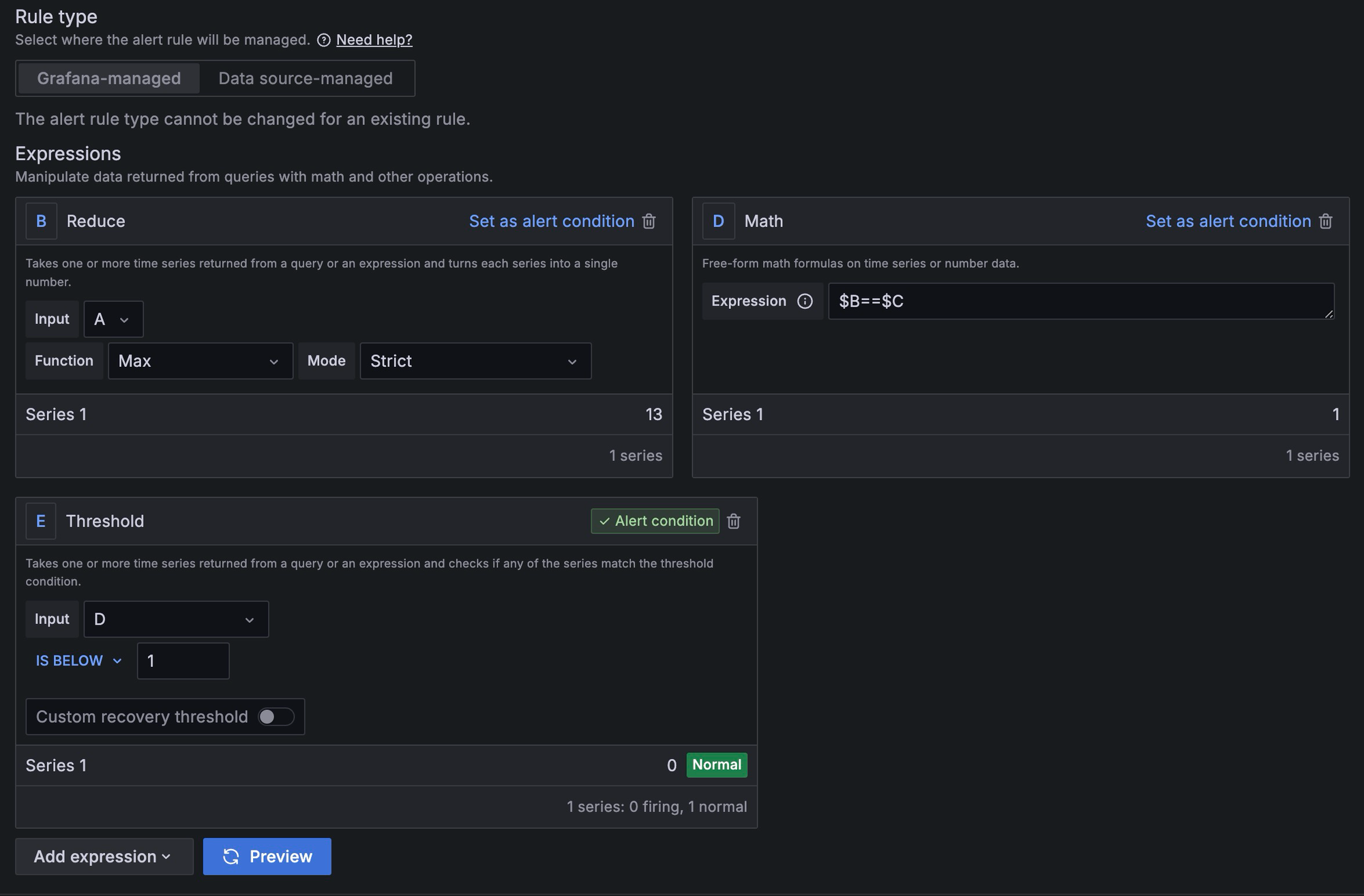
- 다만, 현재는 down 된 서버가 있으면 그냥 알림이 오도록했는데 "어떤 서버가 down 되었는가?" 라는 상세 정보까지는 알 수 없다. 여기에 대해서는 조금 더 찾아봐야겠다.
구조
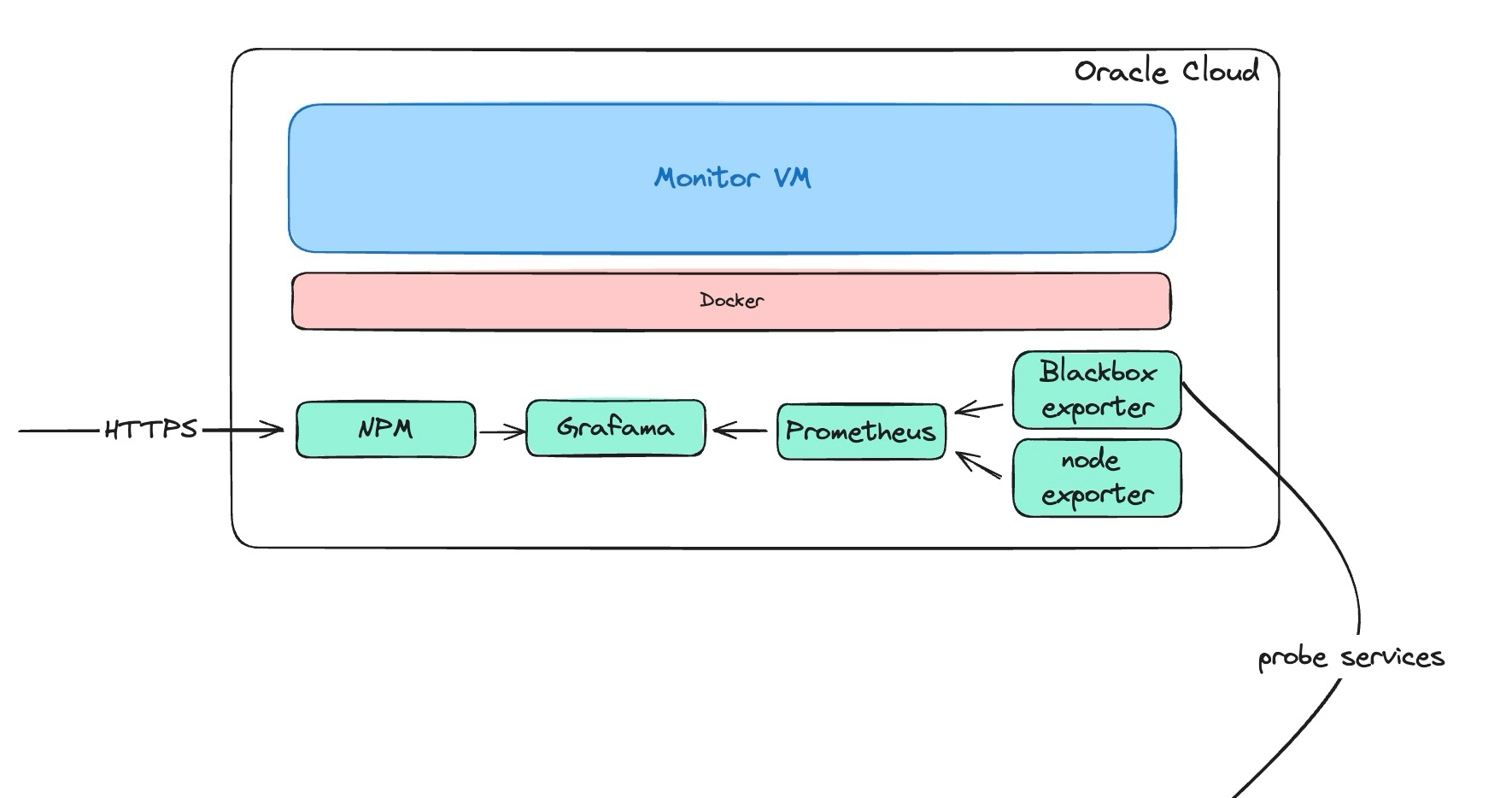
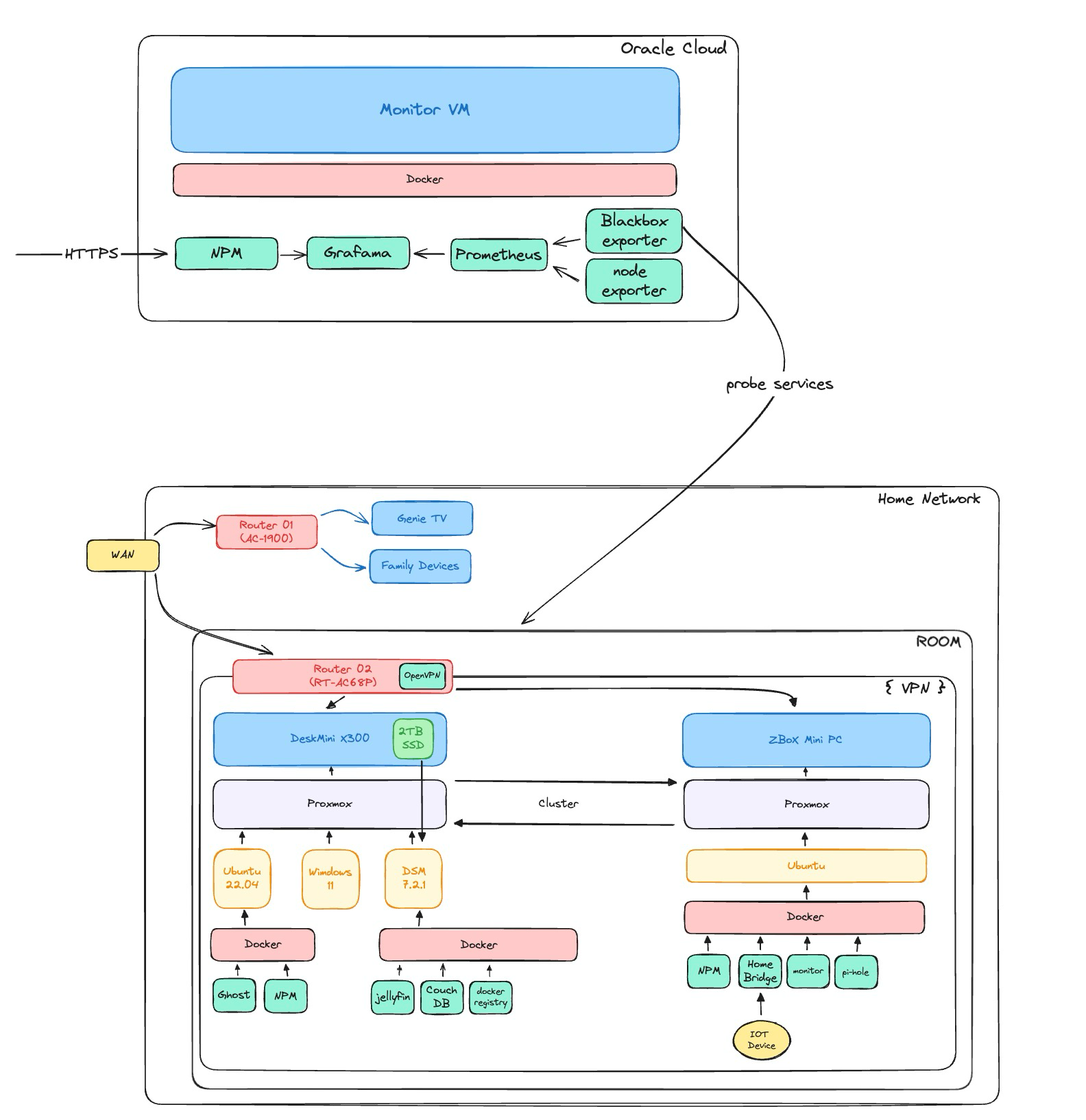
- 결과적으로 위와 같은 구조를 갖추었다. Oracle cloud 위에 있는 VM 에 대한 모니터링과 홈 서버에서 호스팅 중인 서비스의 health check 가 가능하게 되었으며, 서버에 문제가 발생했을 때, 텔레그램으로 알림이 온다.
- Oracle Cloud 가 중단되는 경우를 대비하여 홈서버 측에서도 클라우드에 대한 모니터링을 고려해볼 수도 있겠다. 다만, 이는 나중에 하는 것으로 우선은 미뤄두자.
Cloud 네트워크 설정
Reverse Proxy 설정
- Reverse Proxy 의 경우 Nginx Proxy Manager 를 활용했다.
- 설정 중에 몇 가지 문제가 있었다.
- aarch64 환경에서 SSL 문제
- 기존 홈 서버의 경우 x86 환경이었다. 별다른 이슈 없이 cloudflare 의 api 를 활용해서 Lets encrypt + certbot 을 활용할 수 있었다.
- 그러나, 이번의 경우 certbot 쪽에서 알 수 없는 문제가 발생했다. 다행히 해당 이슈가 github 에 있었다. 현재 latest 버전은 해결이 되어있지 않으나, 문제를 해결하고 있는 버전으로 변경하여 해결했다.
certbot-dns-cloudflare install fails. · Issue #2381 · NginxProxyManager/nginx-proxy-manager
Checklist Have you pulled and found the error with jc21/nginx-proxy-manager:latest docker image? Yes Are you sure you’re not using someone else’s docker image? Yes Have you searched for similar iss…
 NginxProxyManager
NginxProxyManager- proxy 를 하지 못하는 문제
- 각 서비스에 대해서 도메인을 붙여두고 reverse proxy 를 하고자 했으나, 502 Bad Gateway 가 발생했다.
- NPM 서비스쪽에서 다른 서비스와 도커 네트워크가 일치하지 않아 찾을 수 없는 문제였다.
- 기존에는
localhost:port로 표기했으나, 도커 네트워크 안쪽이라서 안되는 것으로 보였다.
- 기존에는
- compose 파일 자체는 다르나, docker network 는 공유하도록했다.
docker network connect {network} {container}
Ingress 보안 규칙
- 모든 포트로 접속하게 하는 것은 위험하며, 최전방에 Reverse Proxy 를 통해서 접속하도록 하고자 했다.
- 80, 443 포트만 개방하도록 했다.

생각보다 글이 많이 길어져서 홈서버 Proxmox node / Router 모니터링은 다음 글에 이어서 작성하겠다. 이번 글을 통해서 구축한 서버의 구조는 다음과 같다.
홈 서버 모니터링 시스템 Oracle Cloud 로 이전하기 (2)
지난 글에 이어 Oracle Cloud 로 모니터링 시스템을 옮기는 과정을 마저 진행해보겠다. VPN 설치 * 모니터링 서버에서 내부 서비스의 경우 외부로 노출될 이유가 없다. 따라서, VPN 을 통해서만 해당 서버에 접속 할 수 있도록 한다. * 기존에 OpenVPN 을 통해서 VPN 을 구축하고 있어, 해당 서버도 OpenVPN 을 활용하도록 할 것이다. docker
 Sungjun Park
Sungjun Park


