Review - malloc v1
malloc 과제 version 1 리뷰


얼마 전 malloc 을 들고 면접을 다녀온 일이 있었다. 상당히 공을 들인 프로젝트였음에도 불구하고, 일순간 막혀 엉터리 구조를 설명한 나를 발견하고 말았다. 지난 프로젝트들에 대해서 리뷰 글을 작성하면서 설계, 이론, 코드에 대해서 차근차근 리뷰를 해보고자 한다.
내가 개발한 malloc 은 두 가지 버전으로 나뉜다. 미완성 버전인 version 1 과 version 1 의 문제를 딛고 개선한 version 2 이다. 면접 당시 공교롭게도 1년이나 지났던 version 1 에 대해서 깊숙한 질문을 받았는데 굉장히 잘못된 설명을 하고 당황을 많이 했었다. "내가 개발한 코드" 에 대해서 다시 제대로 짚지 못한 나의 잘못이다. 그래서 한번 다시 쭉 뜯어보면서 다시 나의 코드로 가져와보고자 한다.
Version 1
 JuneParkCode
JuneParkCodemalloc 의 경우 총 2가지 버전으로 준비했다. version 1 의 경우 malloc 의 기본 구조를 모방하는데 집중을 하였고, version 2 의 경우 42의 기준 아래에서 최대의 퍼포먼스를 만들어내는데 집중을 하였다.
이번 글에서 정리할 version 1 의 경우 23.07 에 개발한 것으로 벌써 1년이나 지났다. 당시에 처음 malloc 을 접하면서 많은 부분에서 어려움을 겪었었고, 이런 어려움들을 그 당시에 제대로 짚고 넘어가거나 수정하지 않았다. 이번 글에서는 해당 버전을 깊숙히 파보면서 어떤 구조로 짜여있으며, 문제는 무엇이고, 어떤 방식으로 해결할 수 있는 지에 대해서 리뷰해나갈 것이다.
목표
malloc 을 만들면서 메모리의 뒷 편을 제대로 뜯어보고 싶었다. 유저가 요청한 메모리는 어떻게 시스템에서 제공하고 관리하며, 해당 메모리에 접근하는 과정이 Hardware 부터 User 까지 어떻게 이루어지는지 파악하고자하는데 목표를 두었다.
malloc 의 기초
우선, 해당 malloc 을 이해하기 위해서는 malloc 의 기초 동작에 대해서 이해할 필요가 있다. malloc 은 다음과 같은 구조로 동작한다.
- User 는 원하는 사이즈의 메모리 공간을 요구한다.
- malloc 은 자체적으로 가지고 있는 memory pool 에서 해당 크기에 알맞은 block 을 찾아 user 에게 제공한다.
- 이 뒷 편의 일들을 구현하는 것이 malloc 개발이다.
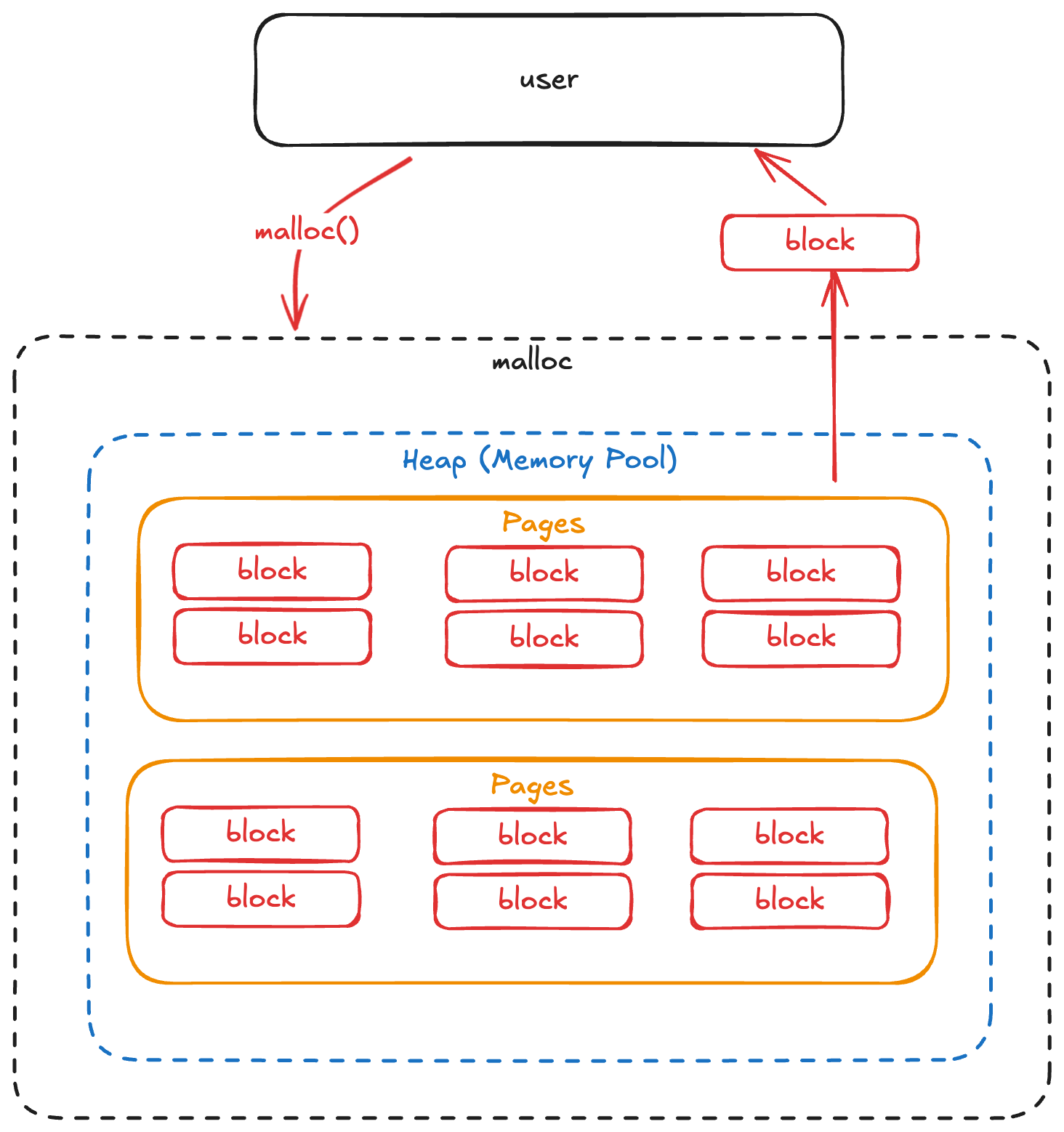
그런데 왜 이런 방식으로 구성이 되는 것일까? malloc 요청 과정을 가볍게 살펴보자.
User 입장에서 dynamic allocation 을 요청할 때 보통 Page 단위가 아닌 16byte, 48byte... 와 같은 작은 크기를 요청하곤 한다. 그러나 OS 에서 Memory 를 관리하는 단위는 이렇게 작은 사이즈의 단위가 아니다. Page 단위로 관리하며 보통 한 page 에 4kb 정도의 공간을 가지고 있다. 이 부분에서 문제가 발생한다.
우선, 시스템에게 메모리를 요청하는 행위는 System call 이다. 따라서 kernel mode 로 전환함과 동시에 내부적으로 page 를 유저에게 할당하는 과정을 수행해야한다. 따라서 이로인한 오버헤드가 존재한다. 또한, 이렇게 할당하는 과정이 4KB 단위의 큰 블록을 던져준다. 고작 8byte 의 공간을 위해서 4KB 의 공간을 제공하는 것은 굉장히 비효율적이다. 이러한 이유에서 System 과 User 사이에서 Heap 공간에 대해서 관리하고 빠르게 Memory block 을 제공하는 것을 목표로 malloc 을 사용한다.
이를 해결하기 위한 방법으로 다양한 접근이 존재하는데 해당 내용은 과거에 작성해뒀던 아래의 글에서 살펴보자.
 Sungjun Park
Sungjun Park
Review
해당 구현을 설명하기에 앞서 이 구현은 잘못된 구현 이라는 것을 강조하고 싶다. Fragmentation 문제, memory leak 문제가 존재하며 block 탐색 / free 시간 또한 굉장히 잘못됐다.
간단하게 설명하면 다음과 같다.
- unsorted / linked list / first-fit / no merge / multi-threaded arena
- 느리고, 메모리 효율도 엉망이다.
조금 더 깊게 구조에 대해서 살펴보자.
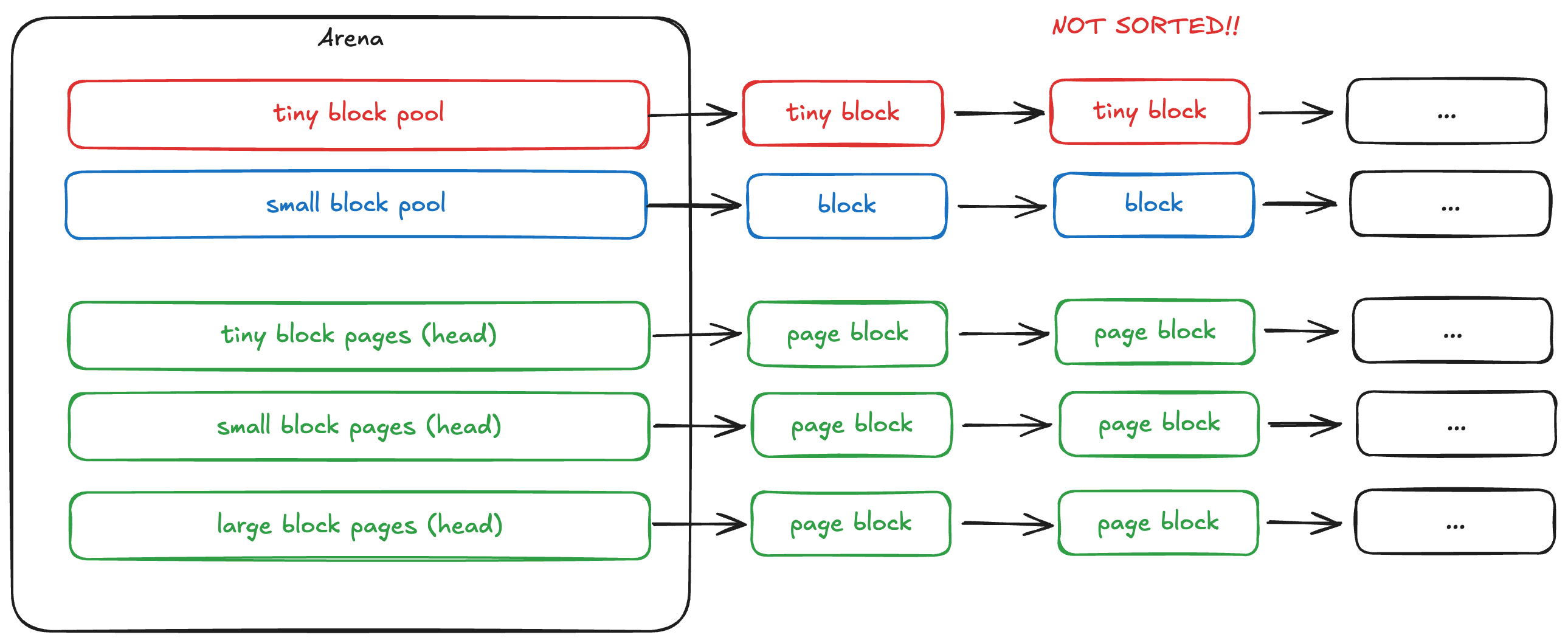
V1 에서는 multi-thread 상황에서의 대응에 조금 더 중점을 맞췄었다. Multi-thread 상황에서는 lock-contention 을 감소시키는 것이 성능 개선의 중점이 되는데, 이를 Arena 라는 공간을 통해서 풀어낸다. Arena 의 경우 사용하는 core 수의 배수로 잡고 배열로 관리한다. 타 thread 에서 동일한 arena 에 접근하거나, 다른 arena 의 block 을 free 하지 않는 이상, arena 의 lock contention 은 arena 개수 만큼 나눈 값으로 줄어든다.
Multi-thread 상황에 대처한 의 경우에도 다시 돌아보면 아쉬운 점이 많다. main arena <-> sub arena 간의 block 전달이 명확하지 않으며, 할당된 arena와 다른 arena 의 block 에 대해서 제대로 처리가 되고 있지 않았다. 또한 thread 에 대해서 별도의 local cache 를 사용하고 있는데, 이 또한 잘 뜯어보면 이상함을 금새 알 수 있었다. (thread 종료 시 해당 block 의 정보를 잃어버린다.)
typedef struct s_metadata {
size_t header; // will be store size + flags(1byte)
struct s_metadata *next_block; // next free block
} t_metadata;
// metadata structure for free tiny block
typedef struct s_tiny_metadata {
size_t header; // will be store size + flags(1byte)
struct s_tiny_metadata *next_block; // next free block
} t_tiny_metadata;
// metadata structure for free small block. at last word, it has sizeof block
typedef struct s_common_metadata {
size_t header; // will be store size + flags(1byte)
struct s_common_metadata *next_block; // next free block
struct s_common_metadata *prev_block; // prev free block
} t_common_metadata;
typedef struct s_page_header {
size_t size;
void *first_block;
struct s_page_header *next;
} t_page_header;
// FOR ARENA
typedef struct s_arena {
pthread_mutex_t lock;
t_tiny_metadata *tiny_free_pool; // tiny pool free head block
t_common_metadata *small_free_pool; // small pool free head block
t_page_header *tiny_page; // tiny page header (allocated page list)
t_page_header *small_page; // small page header (allocated page list)
t_page_header *large_page; // large page header (allocated page list)
} t_arena;
해당 malloc 에서 사용하는 struct 를 코드로 보면 이렇게 구성되어있다. header 부분에 size / flag 를 압축해서 담아두고, 이를 block 앞 단에 위치함으로서 metadata 를 관리하고 있다. tiny block의 경우 최소 allocation size 를 16 byte 로 잡아 prev_block 에 대해서 바라보지 않지만, 그 이상 size 의 block 의 경우 free block 이 되었을 때 추가 정보를 따로 저장해두고 있다.
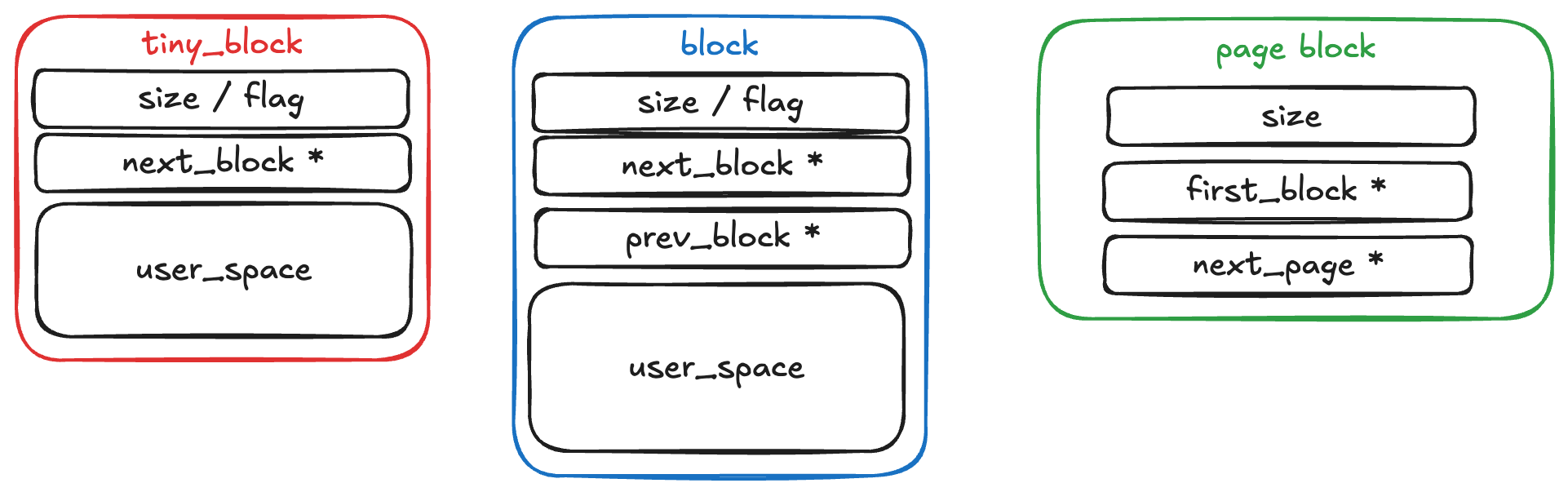
block 의 metadata의 경우에도 다시 살펴보니 상당히 잘못된 구조를 잡고 있다. 단순히 해당 block 의 사이즈 뿐만아니라 prev_block 의 size 를 알고 있어야 free 시에 정상적으로 merge 작업이 가능하다. 그러나, 해당 구현을 살펴보면 해당 block 의 size 만 잡고 있어, PREVE_INUSE flag 로 이전 block 이 사용 중임을 알더라도 이 block 의 metadata 를 알아낼 방도가 존재하지 않는다. (그냥 탐색하는 수 밖에)
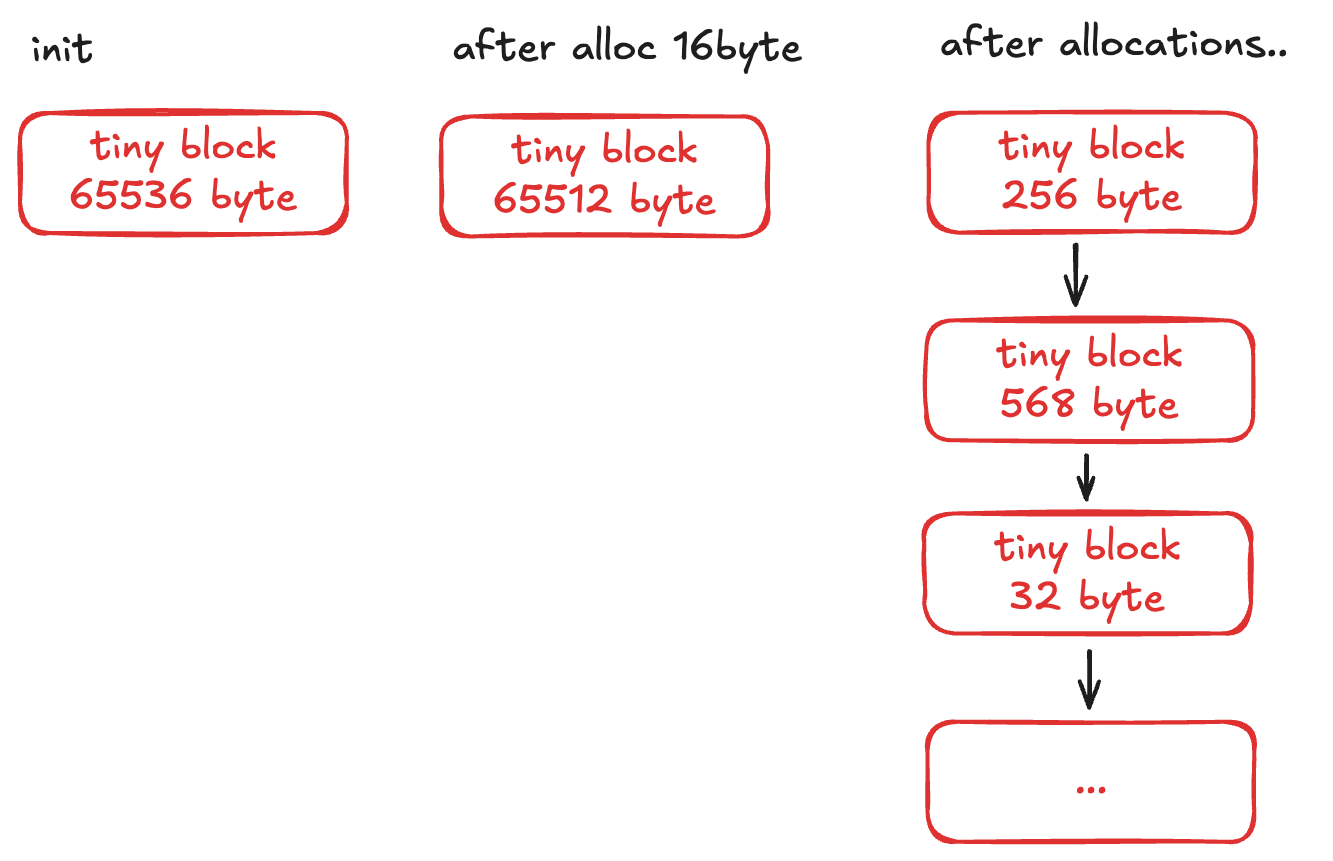
Pool 의 경우 단순 linked list 로 구성하였으며, 각 block 은 처음 상태에서는 pool 의 사이즈를 가지고 있다. (위 그림에서는 65536 byte 가 초기값이나, metadata size 만큼은 제외해야한다.) first-fit 으로 block 탐색을 하며 fit 한 block 이 있는 경우 사용자에게 맞는 block size 로 split 하여 제공한다.
주절주절...
면접 당시에 내가 구현한 malloc 이 O(1) 이라고 소개했는데, 진짜 완전 거짓말을 해버렸던 것이다. 또한 free 에서 merge 작업도 구현하지 않았다. README 에 나중에 다시 구현해야지... 하고 적은 내용이었을 뿐인데, 한 것으로 오해했다. 다시 살펴보니 나도 어이가 없었다. 실제로는 O(N) 이 맞고, fragmentation 이 일어난다. libc 의 구현과 짬뽕으로 머릿속에 박아두어서 v1 의 구현을 완전히 오해하고 있었다.
free 에 대해서는 완전히 잘못 구현했다. 단순히 해당 block을 free 상태로 변경하고, 이를 free list의 head로 다시 반환하는 구조를 가지고 있다. 그런데, 반환시에 merge 작업에 대해서 구현하지 않았다. 코드를 잠시 살펴보면 다음과 같이 되어있다.
void __free_small_block(t_arena *arena, t_tcache *cache,
t_common_metadata *block)
{
int flag = (IS_PREV_USED(block->header) ? FLAG_PREV_USED : 0);
t_arena *block_original_arena =
__find_small_block_original_arena(arena, (t_metadata *)block);
if (block_original_arena == NULL) {
return; // abort() in reference malloc
}
if (block_original_arena == arena) {
flag |= IS_THREADED(block->header) ? FLAG_THREADED : 0;
__set_small_block(block,
SET_HEADER(GET_BLOCK_SIZE(block->header), flag),
cache->small_free_pool, NULL);
if (cache->small_free_pool)
cache->small_free_pool->prev_block = NULL;
cache->small_free_pool = block;
} else {
__set_small_block(block,
SET_HEADER(GET_BLOCK_SIZE(block->header), flag),
block_original_arena->small_free_pool, NULL);
if (block_original_arena->small_free_pool)
block_original_arena->small_free_pool->prev_block = NULL;
block_original_arena->small_free_pool = block;
}
}PREV_USED 를 사용하고 있으나, 그 어디에서도 이를 병합하는 과정이 존재하지 않는다. 또한 prev_block 을 가지고 무언가 처리하고 있지도 않다. (이럴거면 왜 넣어둔건지...) 이로 인해서 block의 파편화가 일어나면서 이후에는 utility가 감소하는 문제가 발생한다. 당시에 어느정도 파악은 해두고 제대로 구현을 해두지 않은 것으로 보인다.
올바른 metadata


기존의 block metadata 의 경우 위와 같이 구성되었다. 위쪽의 size/flag 는 공통된 8byte 의 metadata 공간이며, next_block / prev_block 의 경우 free 시 pool list 에서 사용하는 block 의 포인터를 가지고 있다. flag 내부에서는 블록의 allocation 상태, 이전 block 의 allocation 여부, thread cache 사용 여부 등이 포함된다. (size 의 경우 aligned size 를 이용하면 8 byte / 16 byte 단위로 이루어져 bit 를 아낄 수 있다.)
그러나, 이 구성을 통해서는 free block 의 merge 가 불가능하다. prev_size 를 가지지 않는다면 이전 block 의 위치를 바로 찾을 수가 없다. metadata size 를 증가시켜서라도, merge 가 가능한 구조로 변경하면 이를 해결할 수 있다. 결과적으로는 glibc 의 Metadata 구조와 유사하게 된다.
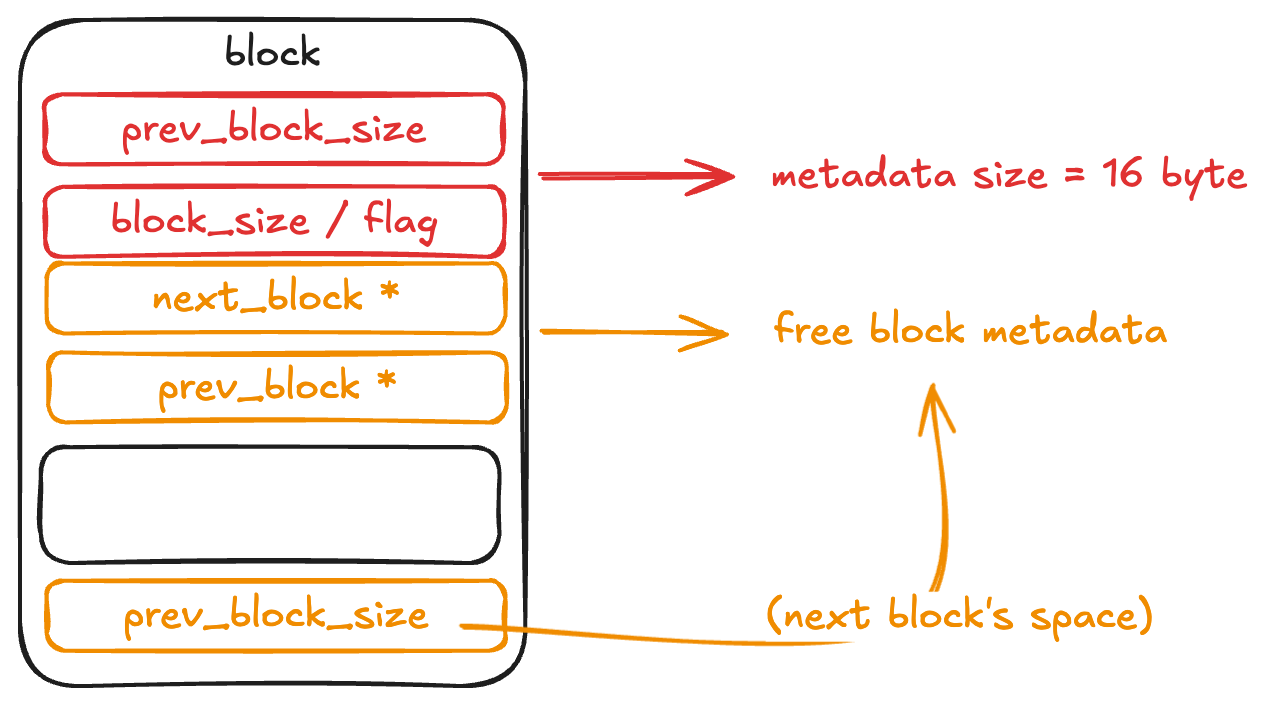
총 16 byte 의 metadata 공간을 할애하여 free 시에 이전 block 의 위치를 탐색할 수 있도록 변경할 수 있다.
Merge 구현 방법
merge 과정이 구현에 포함되지 않았는데, 위 metadata 로 변경하면 다음과 같이 구현할 수 있다.
- free() 호출
- block 의
PREV_USEflag 확인 PREV_USE상태가FREE일 시, 이전 block 의 주소를prev_size를 통해서 획득- 이전 block 의 size 를 현재 block 의 size 와 통합 / 이후 block 의 prev_size 변경
- free list 에 추가
그러나 해당 구현에서는 여전히 문제를 안고 있는데, pool 추가 이후에 다시 해당 공간이 free space 가 되는 경우 해당 pool 을 반환하지 않는다.
탐색 속도 문제
해당 구현의 경우 block 의 split 이 늘어나면, memory fragmentation 이 증가하면서 큰 블록에 대해서 사용할 수 없는 블록이 급증하며 메모리의 효율이 상당히 감소한다. 근본적인 문제는 free-list 가 정렬되어있지 않아, block을 찾는데 상당한 시간이 소요된다는 것이다. 몇 가지 방법으로 탐색 속도를 올려볼 수 있다.
- sorted list 로 유지
- free 시에 O(N) 으로 block 의 사이즈가 큰 순으로 정렬해두고, 이를 탐색하여 사용할 수 있다. first-fit 을 사용할 경우, O(1) 로 block 탐색이 가능하며, best-fit 을 사용할 경우 block 의 사이즈가 작은 경우 O(N)까지 발생가능하다.
- size 별 세분화
- slab allocator 방식을 사용하는 방법이다. 사이즈는 범위가 될 수도 있고, 특정 사이즈의 블록이 될 수도 있다. (glibc 의 경우 두 가지를 모두 사용하고 있다.)
- 특정 사이즈로 나눈 경우 미리 할당해둔 bucket 들을 사용하지 않는 경우에 효율성이 낮아질 수 있으나, 거의 항상 O(1) 로 블록을 제공할 수 있으며, 반환시에도 동일하다.
- 범위로 나눈 경우 first-fit + sorted list 로 유지하면 O(1) 을 기대할 수 있다.다만 split / merge 과정이 포함되어야한다. bucket 마다 block 의 수가 적어지기 때문에 free 시에 O(N) 이나 기존의 N보다는 작다.
구현 상 가장 편리한 방법은 sorted list 가 될 것 같다. 기존의 First fit 방식에 free 시에 적절한 block 의 위치를 찾아 넣으면 되기 때문이다. 그러나, free block 의 개수가 증가하면서 속도가 느려지는 문제를 겪을 것이다. 가장 좋은 방법은 glibc 처럼 혼합형 slab-allocator 를 사용하는 것으로 보인다. 이후 version 2 에서는 해당 문제들을 해결하고자 buddy allocator 를 사용한다.
Pool 조회 / 삭제 문제
Pool 그리고 Large block 의 경우 mmap 을 통해서 page 를 할당받고, 할당 받은 공간에 대한 정보를 가진 뒤, pool 들의 정보를 linked list 로 유지한다. 평소에는 해당 정보에 대해서 조회할 일이 드물지만, page 전체가 free space 가 되는 경우와 large block 을 해제하는 경우 해당 page 가 list 의 어느 공간에 유지되고 있는지 알 수 있어야한다. 그러나 linked list 로 유지되고 있어, 해당 공간을 찾는데 O(N) 의 시간이 소요된다는 문제가 발생하며, large block 을 빈번하게 요청하는 사용 패턴에서 block 의 수가 증가하며 free 의 시간이 증가하는 문제가 발생한다.
glibc 방식과 내 방식에서의 차이에서 비롯되는 문제이기도 한데, glibc 의 경우 main arena 는 sbrk() 로 관리되어, main arena 에서 더 이상 할당할 공간이 없는 경우, sbrk() 를 통해 공간을 확장한다. 따라서 main arena 만 고려한다면, 하나의 주소만 추적하고 있으면 된다. 반면, 해당 구현에서는 (42 과제 상 brk를 허용하지 않아서...) mmap() 만을 통해 이를 구현하는데, 확장된 공간의 정보를 추적하기 위해 list 로 유지하고 있다.
pool 의 경우 확장한 size 를 다시 줄이지 않는 전략을 취하면서 free 에 대한 부담을 줄일 수 있다. (memory peak 이후 점유량이 줄지 않는다는 문제가 있기는 하다.) 그러나 large 의 경우에는 조금 다르다. 현재 구조의 경우 debugging 용도를 위해서 large block 에 대한 정보를 linked list 로 유지하고 있으며, block 에 자체적으로 metadata를 가지고 있으며, 그 자체로 mmap() 으로 할당된 블록이므로 별도의 블록 탐색 과정이 필요하지 않다. 또한, free list 에도 유지할 필요가 없기에 이외의 사용은 없다. (large block 의 경우 반환 즉시 회수하기 때문이다.) 따라서 가장 단순한 방법을 취한다면, large 에 대한 page list 를 삭제하고, block free 시 즉시 munmap 하여 O(1) 로 작업을 종료할 수 있다. (다만 42 기준에 맞추고자한다면, large block 에 대해서도 memory status 를 표시해야하는데, 이를 충족하기 위해서는 별도의 방법이 필요할 것이다.)
후기
당시에 malloc 자체를 처음 접하고 작성했던 코드라 그런지 상당히 아쉬운 점이 많다. 특히, 평가를 받고 난 뒤 생각보다 규모가 더 커질 것 같아 중간에 접어두었는데, 이것을 v1 이라고 써놔도 되는 것일까... 하는 생각도 든다. (그냥 version 을 붙이는 것 자체가 부끄럽다.) 또한 마무리 과정에서 제대로 매듭을 짓지 않아 readme 에 명시된 형태와 다른 것 또한 발견하였고, 이는 다시 코드를 이해하는 과정에서 큰 걸림돌이 되었다.
Multi-thread 상황에 대해서 대응한다고 arena / thread cache 부분에 대해서 상당히 공을 들였는데, 당시에 많이 배우기는 했지만 좋은 선택은 아니었다. arena / thread cache 구조를 다시 살펴보니 상당히 잘못 작성되어있으며, 아예 뜯어고쳐야한다. glibc 를 따라한다면 그 구조를 그대로 가져와야하는데, 어중간하게 들고오면서 완전히 이상한 구조로 프로그래밍을 했다. 그래서 리뷰에 따로 해당 부분은 작성하지 않았다. (새로 접근한다면 아예 다시 공부해서 적용해야할 것으로 보인다.)
이번 리뷰는 이 구현의 구조를 가볍게 뜯어보고 난 뒤, 어떤 문제가 있고 어떻게 해결해야하는지에 대해서 다루었다. 한 번 다시 뜯고 나니까 그래도 어떤 방식으로 접근했는지 명확하게 떠올릴 수 있었다. 그리고 아무래도 시간이 꽤 지나서 그런지 당시에 어렵다고 생각하며 구현 / 설계에서 막혀있던 부분도 금방 금방 풀어나갈 수 있었다. (특히 glibc 구현을 제대로 이해하는게 어려웠었는데, 이제는 다시 보니 볼 만하다.) version 1(?) 은 이정도로 정리해두고 다음에는 제대로 구현한 version 2 를 리뷰해보겠다.
참고 글
- glibc 구현에 대해서 잊고 있었는데, 아래 글이 상당히 깔끔하고 깊게 잘 정리되어있다. 많은 참고를 했다.
 tmxk4221
tmxk4221



